Chapter 11
Advanced Data Management
"The ability to simplify means to eliminate the unnecessary so that the necessary may speak." — Hans Hofmann
Chapter 11 delves into the intricacies of advanced data management within SurrealDB, focusing on the challenges and strategies involved in handling complex data structures across its multi-model architecture. As databases grow in complexity and scale, it becomes increasingly important to manage data in a way that ensures both performance and maintainability. In this chapter, we will explore how to design and optimize data models that span document, graph, and relational paradigms, paying close attention to the unique performance considerations that arise in a multi-model environment. You will learn how to balance data normalization and denormalization, implement efficient indexing strategies, and manage large-scale data migrations. Additionally, we will cover techniques for optimizing queries and data storage to ensure your SurrealDB applications remain responsive and scalable as they grow. By mastering these advanced data management techniques, you'll be equipped to build robust, high-performance applications that can efficiently handle complex, interrelated datasets in SurrealDB.
11.1 Designing Complex Data Models
Effective data modeling stands as a critical component of modern software architecture, particularly essential when handling complex and diverse data structures. In an era dominated by data-driven decisions, the ability to construct versatile and efficient data models directly correlates with the operational success of applications across various domains. SurrealDB, with its innovative multi-model capabilities, provides a unique platform that amalgamates document, graph, and relational models within a single database system. This integration offers a comprehensive environment for addressing the diverse needs of modern applications, from real-time analytics to complex transactional systems.
Comprehensive Exploration of Complex Data Modeling Principles
This section delves deep into the principles of complex data modeling within such a dynamic setup, aiming to uncover strategies that enhance data accessibility, maintain system integrity, and ensure scalability. Through this exploration, we focus on crafting data models that are not only robust and comprehensive but also streamlined and adaptable to the evolving requirements of business applications.
11.1.1 Understanding Data Modeling
In the contemporary data-driven landscape, the art and science of data modeling are paramount, particularly when addressing the complexities inherent in diverse and extensive datasets. With the advent of multi-model databases like SurrealDB, developers are afforded an unprecedented flexibility in managing document, graph, and relational data within a unified platform. This versatility enables the creation of intricate data architectures that can seamlessly handle various data types and relationships, thereby simplifying the development process and enhancing performance.
Data modeling in a multi-model database environment involves more than just the organization of data elements; it encompasses a comprehensive strategy to define and link data in a way that supports both operational efficiency and insightful analytics. In multi-model systems like SurrealDB, where data can be stored as documents, graphs, or relational tables, the complexity increases significantly. Designers must meticulously plan how different data representations will coexist and interact within the same system.
One of the foremost considerations in data modeling is the volume and variety of data. The model must efficiently handle large volumes of varied data types without degrading performance. This involves selecting appropriate data structures and indexing strategies that can manage both the breadth and depth of the data effectively.
Another critical aspect is data relationships. Particularly in graph models, the relationships between data points can be as critical as the data itself. Understanding how entities interconnect allows for the creation of more meaningful and navigable data structures, facilitating advanced queries and analytics.
Query performance is also a pivotal factor. Models must be optimized for the types of queries that will be most frequently run, balancing read and write speeds to ensure swift data retrieval and manipulation. This balance is crucial for applications that require real-time data processing and low-latency responses.
By focusing on these elements, developers can design sophisticated data models that are not only capable of handling current data demands but are also scalable and adaptable to future requirements. This comprehensive approach ensures that the data architecture remains resilient and efficient, supporting the long-term goals of the application and the organization it serves.
11.1.2 Schema Design: Schema-less vs. Schema-based
Choosing between a schema-less and a schema-based approach in SurrealDB involves weighing several factors that pertain to the specific needs and constraints of your application. Each approach offers distinct advantages and trade-offs that can significantly impact the flexibility, performance, and maintainability of your data models.
Schema-less systems provide high flexibility, allowing data structures to evolve without predefined constraints. This is particularly useful in environments where rapid development and iteration are necessary, or where data structures are not fully known in advance. In such scenarios, the ability to modify the data schema on the fly can accelerate development cycles and accommodate changing requirements without necessitating extensive refactoring. Additionally, schema-less designs can handle heterogeneous data more gracefully, making them ideal for applications that ingest data from diverse sources with varying formats.
On the other hand, schema-based systems enforce data structure and integrity from the outset, making them ideal for applications where consistency and reliability are critical. By defining a strict schema, developers can ensure that all data adheres to a specific format, which can prevent errors and inconsistencies that might arise from malformed or unexpected data entries. Schema-based designs can also enhance performance through optimizations that rely on predictable data formats, such as efficient indexing and query planning. Moreover, having a well-defined schema facilitates better documentation and understanding of the data model, which can be beneficial for team collaboration and maintenance.
The choice between these approaches often depends on several key factors, including:
Team Familiarity with Data Models: Teams experienced with schema-based designs may prefer the structure and predictability they offer, while those comfortable with more flexible models might lean towards schema-less designs.
Expected Changes in Data Structure Over Time: Applications anticipated to undergo frequent changes in data requirements may benefit from the adaptability of schema-less systems. Conversely, applications with stable data structures might find schema-based systems more efficient and easier to manage.
Criticality of Data Integrity: In domains where data accuracy and consistency are paramount, such as financial services or healthcare, the enforcement provided by schema-based systems can be invaluable.
Ultimately, the decision between schema-less and schema-based approaches should be guided by a thorough analysis of the application's requirements, the nature of the data being managed, and the operational priorities of the organization.
11.1.3 Balancing Normalization and Denormalization
In any database system, but especially in multi-model environments, balancing normalization and denormalization is crucial for optimizing both performance and maintainability. Striking the right balance ensures that the data model supports efficient data operations while maintaining clarity and reducing redundancy.
Normalization involves organizing data to reduce redundancy and improve integrity through structures that minimize dependency. By dividing data into related tables and establishing clear relationships between them, normalization eliminates duplicate data and ensures that each piece of information is stored in a single, consistent location. This approach simplifies updates and deletions, as changes need to be made in only one place, thereby reducing the risk of data anomalies and inconsistencies.
Conversely, denormalization might increase redundancy but can significantly enhance read performance, which is beneficial in read-heavy scenarios like analytics platforms. By consolidating related data into a single table or document, denormalization reduces the need for complex joins and can accelerate query responses. This can be particularly advantageous in applications where quick data retrieval is more critical than minimizing storage space or ensuring absolute data consistency.
The decision to normalize or denormalize should consider the specific usage patterns anticipated for the application. For instance, applications that perform frequent read operations and require rapid data access may benefit from a denormalized approach. In contrast, applications that prioritize data integrity and handle frequent write operations may find normalization more advantageous.
Additionally, it's essential to consider the potential for future refactoring and the scalability of the data model. Over-normalized structures can become cumbersome and may necessitate significant redesigns as application requirements evolve. Conversely, overly denormalized models can lead to maintenance challenges and data inconsistencies as the application grows.
By carefully evaluating the trade-offs and aligning the normalization strategy with the application's operational needs, developers can create data models that optimize performance while maintaining maintainability and scalability.
11.1.4 Data Integrity Across Models
Maintaining data integrity across different data models within SurrealDB involves ensuring that relationships and data definitions are consistently enforced, which can be challenging given the diverse nature of multi-model databases. Data integrity is paramount to ensure that the database remains a reliable source of truth, free from inconsistencies and errors that could compromise application functionality and user trust.
In SurrealDB, techniques such as maintaining reference integrity in document stores or using graph databases for relationship-heavy data can help ensure that the data remains consistent and reliable. For instance, in a document-based model, embedding references to related documents can maintain context and ensure that related data is easily accessible. Similarly, in a graph-based model, defining clear and consistent edges between nodes can accurately represent relationships and dependencies.
Implementing custom validation logic is another effective strategy for enforcing data integrity across disparate models. By defining rules and constraints that validate data upon insertion or modification, developers can prevent invalid or inconsistent data from entering the database. This can be achieved through the use of SurrealDB's built-in validation features or by integrating custom validation routines within the application logic.
Additionally, database triggers can be employed to enforce complex integrity rules that span multiple data models. Triggers can automatically execute predefined actions in response to specific events, such as ensuring that related records are updated or deleted in tandem. This automation reduces the risk of human error and ensures that integrity rules are consistently applied across all relevant data entities.
Moreover, adopting a transactional approach when performing operations that affect multiple data models can further enhance data integrity. By encapsulating related operations within a single transaction, developers can ensure that either all changes are committed successfully or none are, thereby preventing partial updates that could lead to data inconsistencies.
By leveraging these techniques, developers can maintain robust data integrity across the diverse models supported by SurrealDB, ensuring that the database remains a dependable foundation for application operations and analytics.
11.1.5 Designing for Flexibility and Scalability
To design data models that are both flexible and scalable, several practical approaches can be employed. Flexibility ensures that the data model can adapt to changing business requirements and evolving data structures, while scalability guarantees that the model can handle increasing data volumes and complexity without compromising performance.
One effective strategy is modular design. By structuring data models so that they can evolve independently, modular design allows different components of the data architecture to adapt to changes in business requirements without necessitating wholesale schema redesigns. This approach promotes reusability and simplifies maintenance, as individual modules can be updated or replaced with minimal impact on the overall system.
Implementing scalable indexing strategies is another crucial aspect. As data volumes grow and query complexity increases, efficient indexing becomes essential to maintain optimal performance. SurrealDB offers various indexing options that can be tailored to specific query patterns and data access requirements. By carefully selecting and configuring indexes based on anticipated usage, developers can ensure that the database remains responsive even as the dataset expands.
Moreover, adopting partitioning and sharding techniques can enhance scalability by distributing data across multiple storage units or servers. This not only balances the load but also reduces the risk of bottlenecks, allowing the database to handle larger datasets and higher query volumes more effectively. SurrealDB's multi-model capabilities facilitate the seamless integration of these techniques, ensuring that data distribution aligns with the application's operational needs.
Effective caching mechanisms can also contribute to both flexibility and scalability. By caching frequently accessed data, applications can reduce the load on the database and accelerate data retrieval times. SurrealDB's integration with caching solutions allows developers to implement robust caching strategies that complement the data model, enhancing overall system performance.
Lastly, regular performance monitoring and optimization are essential to maintaining a scalable and flexible data model. By continuously assessing query performance, identifying potential bottlenecks, and adjusting the data model accordingly, developers can ensure that the database remains efficient and capable of supporting the application's growth.
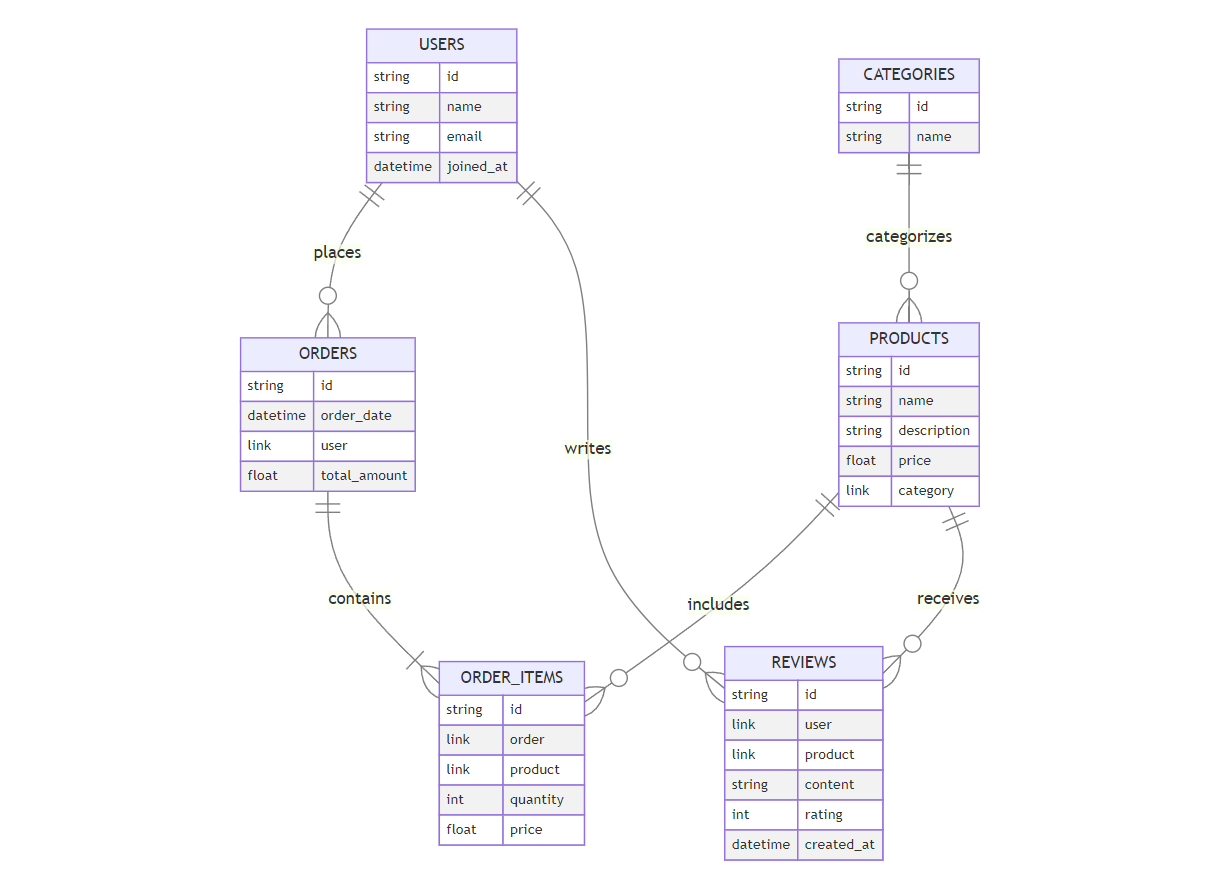
Practical Example: Designing a Complex E-commerce Database
To illustrate the principles discussed, let's consider a real-world case study of designing a complex e-commerce database using SurrealDB. This example will encompass an Entity-Relationship Diagram (ERD) created with Mermaid and provide comprehensive Rust code to interact with the database.
Case Study: E-commerce Platform Database Design
Entity-Relationship Diagram (ERD)
None
Rust Code Example: Interacting with SurrealDB
Below is a comprehensive Rust example demonstrating how to set up SurrealDB, define the data models, and perform CRUD operations for the e-commerce platform.
1. Setting Up Dependencies
First, ensure that you have the necessary dependencies in your Cargo.toml file:
[dependencies]
surrealdb = "1.0" # Replace with the latest version
tokio = { version = "1", features = ["full"] }
serde = { version = "1.0", features = ["derive"] }
serde_json = "1.0"
2. Defining Data Models
Define the data structures corresponding to the entities in the ERD using Rust structs with Serde for serialization.
use serde::{Deserialize, Serialize};
use surrealdb::Surreal;
#[derive(Serialize, Deserialize, Debug)]
struct User { id: String, name: String, email: String, joined_at: String }
#[derive(Serialize, Deserialize, Debug)]
struct Product { id: String, name: String, description: String, price: f64, category: String }
#[derive(Serialize, Deserialize, Debug)]
struct Category { id: String, name: String }
#[derive(Serialize, Deserialize, Debug)]
struct Order { id: String, order_date: String, user: String, total_amount: f64 }
#[derive(Serialize, Deserialize, Debug)]
struct OrderItem { id: String, order: String, product: String, quantity: i32, price: f64 }
#[derive(Serialize, Deserialize, Debug)]
struct Review { id: String, user: String, product: String, content: String, rating: i32, created_at: String }
3. Connecting to SurrealDB
Establish a connection to SurrealDB. Ensure that SurrealDB is running and accessible at the specified URL.
#[tokio::main]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
let db = Surreal::new("http://localhost:8000").await?;
db.signin(surrealdb::opt::auth::Basic { username: "root", password: "root" }).await?;
db.use_ns("ecommerce").use_db("shop").await?;
Ok(())
}
4. Creating Records
Example of creating a new user, category, and product.
let new_user = User { id: "user_1".to_string(), name: "Alice Smith".to_string(), email: "[email protected]".to_string(), joined_at: "2024-04-01T12:00:00Z".to_string() };
db.create("users", &new_user).await?;
let new_category = Category { id: "cat_1".to_string(), name: "Electronics".to_string() };
db.create("categories", &new_category).await?;
let new_product = Product { id: "prod_1".to_string(), name: "Smartphone".to_string(), description: "A high-end smartphone with excellent features.".to_string(), price: 699.99, category: "cat_1".to_string() };
db.create("products", &new_product).await?;
5. Reading Records
Fetching a user by ID.
let user: User = db.select("users", "user_1").await?;
println!("User: {:?}", user);
6. Updating Records
Updating a product's price.
db.update("products", "prod_1").set("price", 649.99).await?;
7. Deleting Records
Deleting an order item.
db.delete("order_items", "item_1").await?;
8. Advanced Querying
Performing a complex query to fetch all orders placed by a specific user, including the products in each order.
// Fetching all orders by a specific user with order items and product details
let query = r#"
SELECT orders.*, order_items.*, products.*
FROM orders
JOIN order_items ON order_items.order = orders.id
JOIN products ON order_items.product = products.id
WHERE orders.user = 'user_1';
"#;
let result: serde_json::Value = db.query(query).await?;
println!("Orders: {:?}", result);
Explanation of the Rust Code
Dependencies: The
surrealdbcrate is used to interact with SurrealDB, whiletokioprovides asynchronous runtime support.serdeandserde_jsonfacilitate serialization and deserialization of data structures.Data Models: Each struct represents an entity in the e-commerce platform. Fields correspond to attributes defined in the ERD, with appropriate data types. Relationships are represented using string references to related entity IDs.
Database Connection: The
Surreal::newfunction establishes a connection to SurrealDB. Authentication is performed using basic credentials, and the appropriate namespace and database are selected.CRUD Operations: The example demonstrates creating new records for users, categories, and products. Reading a user involves selecting a record by its ID. Updating a product's price showcases modifying an existing record, while deleting an order item illustrates removing a record from the database.
Advanced Querying: The complex query example demonstrates how to perform joins across multiple tables to retrieve comprehensive order information, including associated order items and product details. The result is printed in JSON format for readability.
11.2 Indexing and Query Optimization
In the dynamic realm of database management, indexing stands as a cornerstone technology that significantly enhances query performance, particularly in sophisticated multi-model systems like SurrealDB. This section aims to dissect the intricate role of indexing within such a versatile database, exploring various indexing techniques and their direct impact on performance. We delve into how indexing strategies can be optimized to balance query speed with data modification needs, offering a detailed examination of the principles that drive efficient data retrieval and manipulation.
Comprehensive Exploration of Indexing and Query Optimization
Indexing is a fundamental aspect of database optimization, serving as the backbone for efficient data retrieval and manipulation. In multi-model databases like SurrealDB, which support a variety of data structures including relational tables, JSON documents, and graph nodes, the implementation of effective indexing strategies is paramount. Proper indexing ensures that the database can handle complex queries with high performance, thereby enhancing both throughput and responsiveness. This section provides an in-depth analysis of different indexing techniques, their applications, and the trade-offs involved in their implementation. Additionally, it offers practical guidance on optimizing query performance to achieve a harmonious balance between read and write operations.
11.2.1 Introduction to Indexing
Indexing is essential for efficient data retrieval, acting much like a roadmap that allows databases to quickly locate and retrieve data without scanning entire datasets. In multi-model databases like SurrealDB, which accommodate diverse data structures—from relational tables to JSON documents and graph nodes—the implementation of effective indexing strategies becomes critical. Proper indexing ensures that the database can meet the performance requirements of complex queries across different data models, enhancing both throughput and responsiveness.
In essence, an index in a database serves as a data structure that improves the speed of data retrieval operations on a database table at the cost of additional writes and storage space to maintain the index data structure. Without proper indexing, queries that involve searching for specific records can become significantly slower, especially as the size of the dataset grows. SurrealDB leverages its multi-model capabilities to offer a variety of indexing options tailored to different types of data interactions, ensuring that each query can be executed with optimal efficiency.
11.2.2 Types of Indexes
SurrealDB supports a variety of indexing techniques, each designed to optimize performance for different types of data interactions. Understanding the distinct characteristics and appropriate use cases for each index type is crucial for effective database optimization.
B-tree Indexes\ B-tree indexes are commonly used for ordered data operations. They are ideal for a wide range of queries, including those requiring sorted outputs or range-based retrieval. B-tree indexes maintain data in a sorted order, which allows for efficient searching, insertion, and deletion operations. This makes them particularly useful for queries that involve sorting results or retrieving records within a specific range.
Hash Indexes\ Hash indexes are best suited for operations that demand fast data access through equality comparisons. They offer optimal performance for point lookups, where the exact value of a key is known. Unlike B-tree indexes, hash indexes do not maintain any order among the indexed keys, making them less suitable for range queries but highly efficient for direct lookups based on exact matches.
GIN (Generalized Inverted Indexes)\ GIN indexes are especially useful for unstructured data, efficiently handling complex queries involving multiple keys or full-text search capabilities within document and graph data models. They are designed to index composite values and support operations that require searching within array elements or performing text searches. This makes GIN indexes ideal for applications that need to perform sophisticated searches on large volumes of unstructured or semi-structured data.
Spatial Indexes\ For applications dealing with geospatial data, spatial indexes provide efficient querying capabilities for spatial relationships and geometric data types. These indexes enable rapid retrieval of data based on location, proximity, and other spatial criteria, which is essential for applications such as mapping services, location-based analytics, and geographic information systems (GIS).
Full-Text Indexes\ Full-text indexes are optimized for searching within large text fields. They enable efficient querying of textual data, supporting operations like searching for specific keywords, phrases, or patterns within documents. This is particularly useful for applications that require robust search functionalities, such as content management systems, e-commerce platforms, and social media applications.
Each type of index serves a unique purpose and offers distinct advantages depending on the nature of the data and the types of queries being executed. Selecting the appropriate index type is a critical decision that directly impacts the performance and efficiency of the database system.
11.2.3 Optimizing Query Performance
The effectiveness of a query operation in SurrealDB largely depends on how well the indexes are aligned with the query patterns. Optimizing query performance involves a strategic selection of indexes based on the types of queries most frequently executed against the database. Key strategies include:
Selective Indexing\ Implementing indexes specifically on data fields that are most commonly accessed or queried is essential for minimizing unnecessary indexing overhead. By focusing on high-impact fields, selective indexing ensures that the most critical queries benefit from enhanced performance without incurring the additional storage and maintenance costs associated with indexing less frequently accessed data.
Query Plan Analysis\ Regularly analyzing query plans to identify and rectify inefficiencies is crucial for maintaining optimal performance. Query plan analysis involves examining how the database executes queries, identifying bottlenecks, and making adjustments to the indexing strategy to ensure that the most efficient paths are chosen for data access and manipulation. This proactive approach helps in fine-tuning the database to handle evolving query patterns and data distributions effectively.
Index Coverage\ Ensuring that indexes cover the columns involved in query predicates and joins can significantly reduce the need for full table scans. Index coverage means that all the columns referenced in a query's WHERE clause, JOIN conditions, or ORDER BY clause are included in the index, allowing the database to retrieve the necessary data directly from the index without accessing the underlying table.
Composite Indexes\ Creating composite indexes on multiple columns that are frequently used together in queries can enhance performance by allowing the database to efficiently filter and sort data based on multiple criteria simultaneously. Composite indexes are particularly beneficial for complex queries that involve multiple conditions or require sorting on multiple fields.
Partial Indexes\ Partial indexes are built on a subset of the table, typically where certain conditions are met. They can be used to optimize queries that frequently access a specific portion of the data, thereby reducing the size and maintenance overhead of the index while still providing performance benefits for targeted queries.
By implementing these strategies, developers can ensure that their indexing approach is well-aligned with their application's query patterns, thereby maximizing the performance and efficiency of their SurrealDB instances.
11.2.4 Indexing Trade-offs
While indexes are invaluable for enhancing query performance, they also introduce certain trade-offs that need careful consideration. Understanding these trade-offs is essential for making informed decisions about when and how to implement indexing strategies.
Storage and Maintenance Overhead\ Indexes consume additional storage space, which can be significant depending on the size and number of indexes. Moreover, every time data is inserted, updated, or deleted, the corresponding indexes must also be updated to reflect these changes. This maintenance overhead can impact write performance, as additional operations are required to keep the indexes in sync with the data.
Performance Balance\ There is a need to strike a balance between the speed of read operations provided by indexes and the potential slowdown in write operations due to index maintenance. While indexes can dramatically improve read performance, they can also degrade write performance, especially in write-heavy applications. Developers must carefully evaluate the read-write patterns of their applications to determine the optimal indexing strategy that provides the best overall performance.
Complexity in Management\ Managing a large number of indexes can add complexity to the database management process. It requires continuous monitoring and fine-tuning to ensure that indexes remain effective as data volumes and query patterns evolve. Over-indexing can lead to increased maintenance costs and diminished returns, while under-indexing can result in suboptimal query performance.
Impact on Data Ingestion\ In scenarios where the database is subject to high rates of data ingestion, the overhead of maintaining indexes can become a bottleneck. This can lead to increased latency in data processing and delays in making new data available for querying. Careful consideration of indexing strategies is necessary to mitigate the impact on data ingestion rates.
Trade-offs in Index Design\ Different indexing techniques come with their own set of trade-offs in terms of performance, storage, and maintenance. For example, while B-tree indexes are versatile and support a wide range of queries, they may not be as efficient as hash indexes for specific use cases like exact-match lookups. Similarly, GIN indexes provide powerful capabilities for handling unstructured data but can consume more storage space compared to other index types.
By weighing these trade-offs, developers can make informed decisions about the most appropriate indexing strategies for their specific use cases, ensuring that the benefits of indexing outweigh the associated costs.
11.2.5 Implementing Effective Indexing
To effectively implement and tune indexes in SurrealDB, it is important to undertake a methodical approach that encompasses evaluation, implementation, and continuous optimization. This ensures that the indexing strategy remains aligned with the evolving needs of the application and the data it manages.
Evaluate Common and Performance-Critical Queries\ The first step in implementing effective indexing is to thoroughly evaluate the most common and performance-critical queries that the application executes. By understanding the query patterns and identifying the fields and conditions that are frequently used, developers can determine which indexes will provide the most significant performance improvements.
Implement Indexes Judiciously\ Once the key queries have been identified, indexes should be implemented judiciously, focusing on the fields and data types that are critical to query performance. This involves selecting the appropriate type of index (e.g., B-tree, hash, GIN) based on the nature of the data and the types of queries being optimized. Care should be taken to avoid over-indexing, which can lead to unnecessary storage and maintenance overhead.
Continuously Monitor and Adjust Indexing Strategies\ Indexing is not a one-time task but an ongoing process that requires continuous monitoring and adjustment. As the application evolves and data access patterns change, the indexing strategy may need to be updated to maintain optimal performance. Regular performance monitoring, combined with query plan analysis, can help identify opportunities for refining the indexing approach to better align with current usage patterns.
Leverage SurrealDB's Indexing Features\ SurrealDB offers a range of indexing features that can be leveraged to enhance query performance. This includes the ability to create composite indexes, partial indexes, and utilizing advanced indexing techniques like GIN for unstructured data. Understanding and utilizing these features can help in crafting a robust indexing strategy that maximizes the performance benefits while minimizing the associated costs.
Automate Index Management\ Where possible, automate aspects of index management to reduce the burden on developers and ensure consistency. This can include automating the creation and updating of indexes based on predefined rules or integrating indexing strategies into the application's deployment and scaling processes. Automation can help in maintaining an effective indexing strategy without requiring constant manual intervention.
By following these best practices, developers can implement and maintain an effective indexing strategy that enhances the performance and efficiency of their SurrealDB instances, ensuring that the database can handle the demands of modern applications with ease.
Practical Example: Optimizing an E-commerce Database with Indexes
To illustrate the principles discussed, let's consider a real-world case study of optimizing an e-commerce database using SurrealDB. This example will encompass an Entity-Relationship Diagram (ERD) created with Mermaid and provide comprehensive Rust code to interact with the database, demonstrating the implementation of various indexing strategies and their impact on query performance.
Entity-Relationship Diagram (ERD)

None
Rust Code Example: Implementing Indexing and Query Optimization in SurrealDB
Below is a comprehensive Rust example demonstrating how to set up SurrealDB, define the data models, implement indexing strategies, and perform optimized queries for the e-commerce platform.
1. Setting Up Dependencies
First, ensure that you have the necessary dependencies in your Cargo.toml file:
[dependencies]
surrealdb = "1.0" # Replace with the latest version
tokio = { version = "1", features = ["full"] }
serde = { version = "1.0", features = ["derive"] }
serde_json = "1.0"
2. Defining Data Models
Define the data structures corresponding to the entities in the ERD using Rust structs with Serde for serialization.
use serde::{Deserialize, Serialize};
use surrealdb::Surreal;
// Define the data structures
#[derive(Serialize, Deserialize, Debug)]
struct User { id: String, name: String, email: String, joined_at: String }
// More struct definitions follow...
3. Connecting to SurrealDB
Establish a connection to SurrealDB. Ensure that SurrealDB is running and accessible at the specified URL.
// Main function to connect to SurrealDB
#[tokio::main]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
let db = Surreal::new("http://localhost:8000").await?;
db.signin(surrealdb::opt::auth::Basic { username: "root", password: "root" }).await?;
db.use_ns("ecommerce").use_db("shop").await?;
Ok(())
}
4. Creating Records with Indexes
Implementing indexes on frequently queried fields such as email in users, name in products, and order_date in orders.
// Code to define indexes and create records
db.query("DEFINE INDEX email_idx ON users (email) TYPE hash;").await?;
// Additional indexing and record creation follow...
5. Reading Records with Indexed Fields
Fetching a user by their indexed email to demonstrate the performance benefits of indexing.
// Query to fetch user by indexed email
let query = "SELECT * FROM users WHERE email = '[email protected]';";
let result: serde_json::Value = db.query(query).await?;
println!("User: {:?}", result);
6. Updating Records and Index Maintenance
Updating a product's price and observing how the index is maintained.
// Update the product's price and verify
db.query("UPDATE products SET price = 649.99 WHERE id = 'prod_1';").await?;
// Fetch to confirm update
7. Deleting Records and Index Cleanup
Deleting an order item and ensuring the associated index is updated accordingly.
// Code to delete order item and verify deletion
let delete_query = "DELETE FROM order_items WHERE id = 'item_1';";
db.query(delete_query).await?;
8. Advanced Querying with Optimized Indexes
Performing a complex query to fetch all orders placed by a specific user, including the products in each order, utilizing the indexes to enhance performance.
#[tokio::main]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
// Connect to the database
let db = Surreal::new("http://localhost:8000").await?;
// Sign in as a namespace and database
db.signin(surrealdb::opt::auth::Basic {
username: "root",
password: "root",
})
.await?;
// Select the namespace and database
db.use_ns("ecommerce").use_db("shop").await?;
// Complex query to fetch all orders by a specific user with order items and product details
let complex_query = r#"
SELECT orders.*, order_items.*, products.*
FROM orders
JOIN order_items ON order_items.order = orders.id
JOIN products ON order_items.product = products.id
WHERE orders.user = 'user_1';
"#;
let result: serde_json::Value = db.query(complex_query).await?;
println!("User's Orders with Details: {:?}", result);
Ok(())
}
Explanation of the Rust Code
Dependencies\
The surrealdb crate is used to interact with SurrealDB, while tokio provides asynchronous runtime support. serde and serde_json facilitate serialization and deserialization of data structures.
Data Models\
Each struct represents an entity in the e-commerce platform. Fields correspond to attributes defined in the ERD, with appropriate data types. Relationships are represented using string references to related entity IDs.
Database Connection\
The Surreal::new function establishes a connection to SurrealDB. Authentication is performed using basic credentials, and the appropriate namespace and database are selected.
Index Creation\
Indexes are defined on critical fields such as email in users, name in products, and order_date in orders. These indexes are of different types (hash and B-tree) based on the nature of the queries they support.
CRUD Operations\
The example demonstrates creating new records for users, categories, products, orders, order items, and reviews. Reading a user by their indexed email showcases the performance benefits of indexing. Updating a product's price and deleting an order item illustrate how indexes are maintained during data modifications.
Advanced Querying\
The complex query example demonstrates how to perform joins across multiple tables to retrieve comprehensive order information, including associated order items and product details. The result is printed in JSON format for readability, highlighting how indexes improve the efficiency of such queries.
Indexing and query optimization are pivotal for achieving high performance and efficiency in multi-model databases like SurrealDB. By understanding the various types of indexes, their appropriate applications, and the trade-offs involved, developers can craft indexing strategies that significantly enhance query performance while maintaining a balance with write operations. The integration of Rust further amplifies these benefits, providing a robust and efficient environment for building scalable and high-performing applications. Through thoughtful design and strategic implementation of indexing techniques, SurrealDB and Rust together offer a powerful combination for managing complex data in modern software systems.
11.3 Managing Large-Scale Data
In the vast and complex realm of database management, handling large-scale data efficiently poses significant challenges, particularly within the context of multi-model databases like SurrealDB. These systems must seamlessly manage, retrieve, and store vast amounts of diverse data without compromising on performance. This section delves into the intricate challenges and strategies associated with large-scale data management, emphasizing data partitioning and sharding, scalability tactics, and data transformation processes. Through a detailed exploration, we aim to provide a comprehensive understanding of the techniques and methodologies essential for optimizing large-scale data environments.
Comprehensive Exploration of Large-Scale Data Management
Managing large-scale data in multi-model databases like SurrealDB requires a multifaceted approach that addresses the complexities of storage, performance, scalability, and data integrity. As data volumes grow exponentially, the ability to efficiently partition, shard, and migrate data becomes paramount. Additionally, implementing robust scalability strategies ensures that the database can handle increasing workloads without degradation in performance. This section provides an in-depth analysis of the challenges posed by large-scale data and offers practical strategies for overcoming them, ensuring that your database remains performant, scalable, and manageable as it evolves.
11.3.1 Challenges of Large-Scale Data
Managing large datasets in multi-model databases presents a series of unique challenges that impact storage, performance, and scalability. These challenges are compounded by the diverse nature of data handled by multi-model systems like SurrealDB, which must support various data structures and access patterns. Understanding these challenges is crucial for developing effective strategies to mitigate them.
Storage Efficiency
As data accumulates, the physical storage requirements grow exponentially. Efficient storage solutions must not only accommodate the sheer volume but also support quick data retrieval. In multi-model databases, this involves optimizing storage formats for different data types—whether they are relational tables, JSON documents, or graph nodes. Techniques such as data compression, efficient encoding schemes, and storage tiering become essential to manage storage costs and ensure that frequently accessed data remains readily available.
Moreover, managing storage efficiency also involves implementing effective data lifecycle policies. This includes archiving infrequently accessed data to cheaper storage solutions and ensuring that active data remains on high-performance storage media. SurrealDB’s flexible storage capabilities allow for the seamless integration of such policies, enabling organizations to balance cost and performance effectively.
Performance Optimization
Large-scale data can dramatically slow down database operations. Optimizing query performance and ensuring swift data manipulation become crucial as the dataset grows. Performance optimization in SurrealDB involves fine-tuning indexing strategies, optimizing query execution plans, and leveraging caching mechanisms to reduce latency. Additionally, efficient use of SurrealDB’s multi-model capabilities can help distribute the load more evenly across different data structures, preventing bottlenecks and ensuring that the database remains responsive under heavy workloads.
Performance optimization also requires continuous monitoring and profiling of database operations. Tools that provide insights into query performance, resource utilization, and potential bottlenecks are invaluable. By regularly analyzing these metrics, developers can identify areas for improvement and implement optimizations that enhance overall system performance.
Scalability Concerns
Scaling a database to support increasing amounts of data involves complex decisions regarding architecture and resource allocation. Both hardware limitations and software configurations must be addressed to ensure that the database can scale without performance degradation. SurrealDB offers various scalability options, including horizontal scaling (adding more nodes) and vertical scaling (upgrading existing hardware).
Horizontal scaling distributes the load across multiple servers, enhancing the database's ability to handle more simultaneous operations and increasing fault tolerance. Vertical scaling, while potentially more costly, can provide significant immediate boosts in performance by leveraging more powerful hardware resources. Deciding between these scaling methods depends on factors such as budget constraints, expected data growth, and performance requirements.
Furthermore, ensuring data consistency and integrity across a scaled-out environment presents additional challenges. SurrealDB’s robust replication and consistency mechanisms help maintain data integrity while supporting scalable architectures, enabling databases to grow seamlessly without sacrificing reliability.
11.3.2 Data Partitioning and Sharding
To manage large-scale data effectively, partitioning and sharding are essential techniques that help distribute data across multiple storage units or servers. These strategies not only enhance performance but also improve data availability and fault tolerance.
Data Partitioning
Data partitioning involves dividing a database into smaller, more manageable segments called partitions. Each partition can be processed faster and more efficiently, reducing the overall load on the system. Partitioning can be based on specific criteria such as range, list, or hash, depending on the nature of the data and the queries typically run against it.
Range Partitioning: This method divides data based on ranges of values. For example, in an e-commerce database, orders could be partitioned by date ranges (e.g., monthly partitions). Range partitioning is particularly useful for time-series data where queries often target specific time periods.
List Partitioning: Data is partitioned based on predefined lists of values. For instance, a customer database might be partitioned by geographical regions, with each partition containing customers from a specific region.
Hash Partitioning: This approach uses a hash function to distribute data evenly across partitions. Hash partitioning is ideal for scenarios where data access patterns are unpredictable, ensuring a balanced distribution of data and preventing any single partition from becoming a bottleneck.
Implementing effective data partitioning in SurrealDB involves identifying key attributes that frequently determine how data is accessed. These attributes guide decisions on how to partition the data to optimize access and query performance.
Sharding
Sharding is an extension of partitioning that distributes data across multiple physical environments or servers, allowing databases to manage more data than could be handled on a single machine. Sharding not only enhances performance by distributing the load but also adds redundancy and increases availability. In the event of a server failure, other shards can continue to operate, ensuring that the database remains accessible.
Sharding in SurrealDB can be implemented by defining shard keys that determine how data is distributed across different nodes. Selecting an appropriate shard key is crucial for ensuring an even distribution of data and preventing hotspots—situations where one shard handles a disproportionate amount of traffic or data.
Shard Key Selection: The shard key should be chosen based on data access patterns to ensure that queries can be efficiently routed to the appropriate shards. For example, in a user-centric application, the user ID might serve as an effective shard key, distributing user data evenly across shards and allowing for efficient user-specific queries.
Shard Management: Effective shard management involves monitoring shard health, balancing data distribution, and handling shard rebalancing as data grows. SurrealDB’s built-in tools and APIs facilitate the management of shards, enabling administrators to monitor shard performance and redistribute data as needed to maintain optimal performance and availability.
11.3.3 Scalability Strategies
Scalability is a critical aspect of managing large-scale databases effectively. SurrealDB incorporates various strategies to accommodate growing data demands, ensuring that the database can handle increasing workloads without compromising performance.
Horizontal Scaling
Horizontal scaling involves adding more nodes to the database cluster to distribute the load evenly. This method enhances the database's ability to handle more simultaneous operations and increases fault tolerance. By spreading data and query processing across multiple nodes, horizontal scaling ensures that no single node becomes a performance bottleneck.
Advantages of Horizontal Scaling:
Improved Performance: Distributes the workload across multiple servers, enhancing overall throughput.
Fault Tolerance: Redundancy is inherently increased, as data is replicated across multiple nodes, ensuring high availability.
Flexibility: Easier to add or remove nodes based on demand, allowing the system to adapt dynamically to changing workloads.
Implementation in SurrealDB: SurrealDB supports horizontal scaling through its clustering capabilities. By adding more nodes to the cluster, data is automatically distributed, and queries are load-balanced across the available nodes. This seamless integration ensures that scaling operations do not disrupt ongoing database activities.
Vertical Scaling
Vertical scaling involves upgrading the existing hardware capabilities of the system to support more data and more complex operations. This can include adding more CPU cores, increasing memory, or utilizing faster storage solutions. While potentially more costly, vertical scaling can provide a significant immediate boost in performance.
Advantages of Vertical Scaling:
Simplicity: Easier to implement compared to horizontal scaling, as it involves upgrading existing hardware rather than managing multiple nodes.
Immediate Performance Gains: Provides a direct and noticeable improvement in performance by enhancing the capabilities of individual servers.
Disadvantages of Vertical Scaling:
Cost: High-performance hardware can be expensive, and there are physical limitations to how much a single machine can be upgraded.
Limited Scalability: Unlike horizontal scaling, vertical scaling has inherent limits and cannot address extremely large datasets or high concurrency demands.
Implementation in SurrealDB: While SurrealDB primarily leverages horizontal scaling for its scalability, vertical scaling can still play a role in optimizing performance for specific nodes within the cluster. Upgrading hardware on critical nodes can enhance their capacity to handle more intensive operations, contributing to overall system performance.
Combined Scaling Strategies
In practice, combining horizontal and vertical scaling strategies can offer the best of both worlds, providing both increased capacity and enhanced performance. By horizontally scaling to distribute the load and vertically scaling individual nodes to handle more intensive operations, databases can achieve a high level of scalability and resilience.
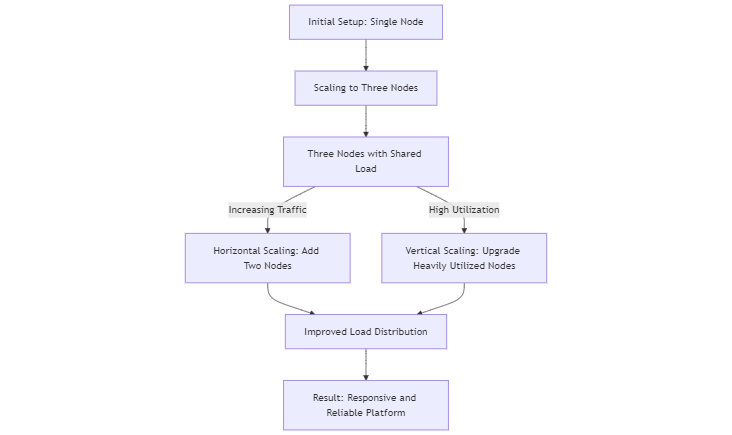
Case Study: Scaling an E-commerce Platform with SurrealDB
Consider an e-commerce platform experiencing rapid growth in user traffic and transaction volumes. To maintain performance and availability, the platform implements a combined scaling strategy using SurrealDB.
Initial Setup: The database cluster starts with three nodes, each handling a portion of the data and query load.
Horizontal Scaling: As user traffic increases, two additional nodes are added to the cluster, distributing the load more evenly and preventing any single node from becoming overwhelmed.
Vertical Scaling: Concurrently, the most heavily utilized nodes are upgraded with additional CPU cores and increased memory to handle more complex queries and higher transaction rates.
Result: The combined scaling approach ensures that the e-commerce platform remains responsive and reliable, even as data volumes and user traffic continue to grow.
None
11.3.4 Data Migration and Transformation
As databases evolve, data migration and transformation become necessary processes, particularly when upgrading systems or integrating new features. Effective migration strategies ensure that data remains consistent and intact throughout the process, while data transformation aligns with new system requirements or optimizes performance in the new environment.
Data Migration
Data migration is the process of moving data from one system to another. This might be necessary during upgrades, when transitioning to new hardware, or when integrating with other applications. Successful data migration requires meticulous planning to ensure data integrity and minimal downtime.
Key Steps in Data Migration:
Assessment and Planning: Evaluate the existing data, identify migration requirements, and plan the migration process.
Data Mapping: Define how data from the source system maps to the target system, ensuring that all necessary data is accounted for.
Data Extraction: Extract data from the source system in a consistent and reliable manner.
Data Transformation: Convert data into a format compatible with the target system, if necessary.
Data Loading: Import the transformed data into the target system.
Validation and Testing: Verify that the data has been accurately migrated and that the target system functions as expected.
Cutover and Monitoring: Transition to the new system and continuously monitor for any issues.
Data Migration in SurrealDB: SurrealDB provides robust APIs and tools to facilitate data migration. Whether migrating from another database system or consolidating data from multiple sources, SurrealDB’s flexible data model and multi-model capabilities simplify the migration process. Additionally, SurrealDB’s support for transactions ensures that data integrity is maintained throughout the migration process.
Data Transformation
Data transformation involves changing the format, structure, or scope of the data as it is migrated. This might be necessary to align with new system requirements, optimize data for performance, or integrate with other applications.
Common Data Transformation Tasks:
Schema Evolution: Modifying the data schema to support new features or data types.
Data Cleaning: Removing duplicates, correcting errors, and standardizing data formats.
Data Aggregation: Combining data from multiple sources or summarizing data for reporting purposes.
Format Conversion: Changing data formats (e.g., from CSV to JSON) to match the requirements of the target system.
Data Transformation in SurrealDB: SurrealDB’s versatile data model supports seamless data transformation. Whether dealing with structured relational data, semi-structured JSON documents, or interconnected graph data, SurrealDB provides the flexibility needed to adapt data structures to evolving requirements. Rust’s powerful data manipulation capabilities, combined with SurrealDB’s multi-model features, enable efficient and effective data transformation processes.
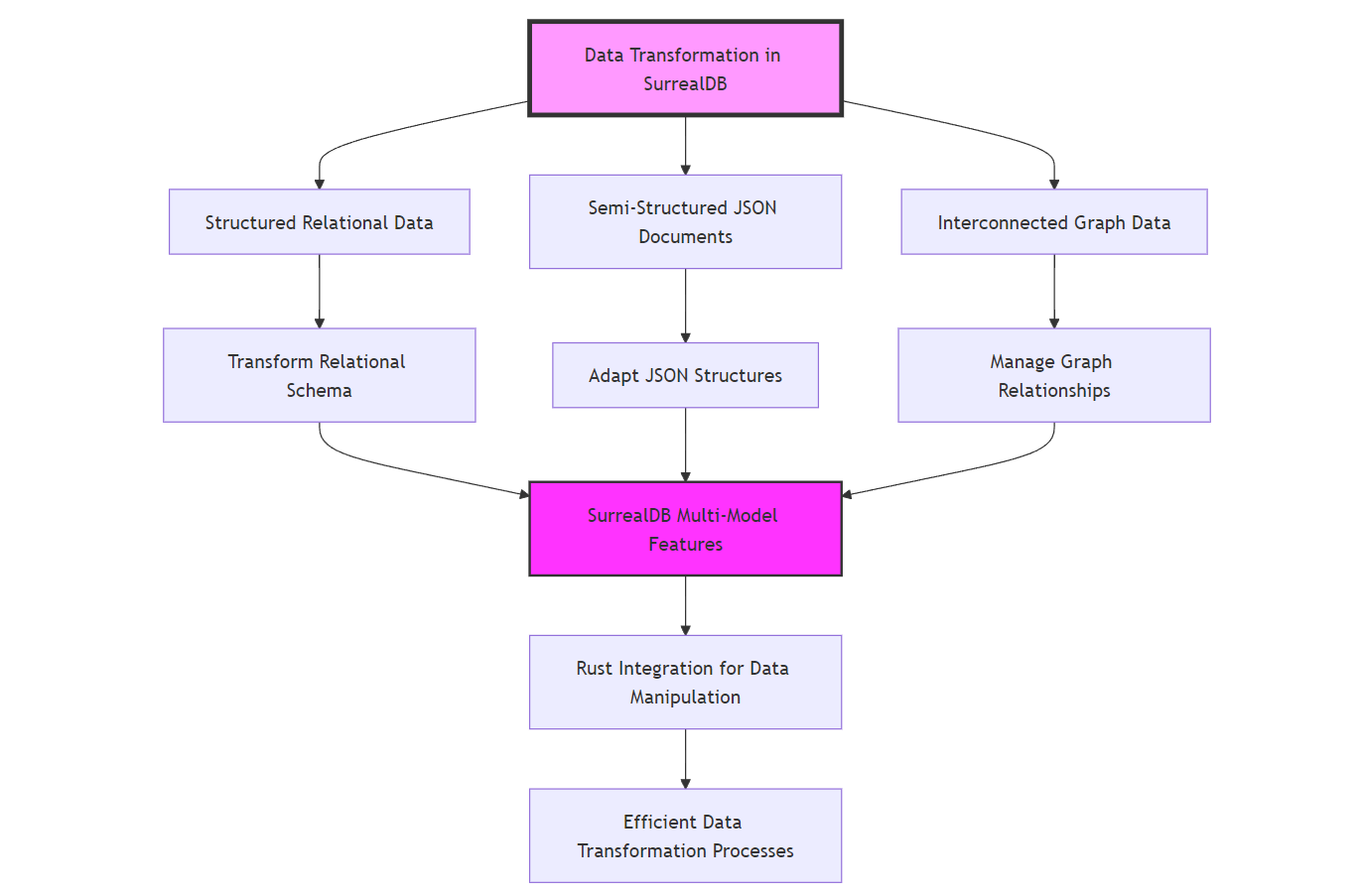
None
This diagram illustrates the process of data transformation within SurrealDB, showcasing its ability to handle various data types seamlessly. The transformation process begins with the initial identification of different data models that SurrealDB supports, including structured relational data, semi-structured JSON documents, and interconnected graph data.
For structured relational data, SurrealDB enables the transformation of traditional relational schemas, ensuring compatibility and flexibility when changes are required. When dealing with semi-structured JSON documents, SurrealDB supports the adaptation of JSON structures, allowing easy manipulation and adjustment based on evolving data needs. Interconnected graph data represents another type of data structure, and SurrealDB efficiently manages the complex relationships that exist within these data models.
These data types are processed using SurrealDB's multi-model features, which provide a unified platform to handle diverse data structures, ensuring that all data is compatible and can be transformed as needed. The integration with Rust further enhances this capability, leveraging Rust’s powerful data manipulation features to perform efficient transformations. This combination ensures that the data transformation processes are not only effective but also optimized for performance.
The result is a system that can adapt to evolving requirements, transform various data types, and manage complex data structures efficiently, making SurrealDB an ideal choice for projects requiring flexibility and robustness in data handling. This comprehensive approach enables seamless data management and transformation, crucial for modern, dynamic applications.
11.3.5 Implementing Data Partitioning
Implementing data partitioning in SurrealDB involves several steps designed to ensure that data is distributed effectively across multiple nodes. Proper partitioning not only enhances performance but also facilitates easier management and scalability of large datasets.
Identify Key Attributes
The first step in implementing data partitioning is identifying the key attributes that frequently determine how data is accessed. These attributes will guide decisions on how to partition the data to optimize access and query performance. For instance, in an e-commerce database, attributes such as user_id, order_date, or product_category might be pivotal in determining how data should be partitioned.
Example: If most queries involve retrieving orders by date, partitioning orders based on order_date can significantly enhance query performance by limiting the search scope to specific partitions.
Decide on the Partitioning Scheme
Choosing the appropriate partitioning scheme is crucial for effective data distribution. SurrealDB supports various partitioning schemes, each offering different advantages based on the data and access patterns.
Range Partitioning: Divides data based on ranges of values. Suitable for time-series data where queries often target specific time intervals.
List Partitioning: Divides data based on predefined lists of values. Ideal for categorical data such as geographical regions or product categories.
Hash Partitioning: Uses a hash function to distribute data evenly across partitions. Best suited for scenarios where data access patterns are unpredictable, ensuring a balanced load across partitions.
Composite Partitioning: Combines multiple partitioning schemes to cater to complex data access patterns. For example, first applying range partitioning on order_date and then hash partitioning on user_id within each date range.
Apply the Chosen Partitioning Scheme
Once the partitioning scheme is selected, the next step is to apply it within SurrealDB. This involves configuring the database to automatically distribute data based on the defined partitioning rules. Proper alignment with anticipated access patterns is essential to reduce latency and prevent load imbalances.
Implementation Steps:
Define Partition Keys: Specify the attributes that will determine data distribution.
Configure Partitioning Rules: Set up the partitioning scheme within SurrealDB’s configuration or using its API.
Distribute Data: Insert data into the database, allowing SurrealDB to automatically partition it based on the defined rules.
Monitor and Adjust: Continuously monitor data distribution and query performance, making adjustments to partitioning rules as necessary to maintain optimal performance.
Practical Example: Implementing Partitioning in SurrealDB
Let’s consider implementing range partitioning based on order_date for an e-commerce platform’s orders data.
Rust Code Example: Setting Up Range Partitioning
Below is a Rust example demonstrating how to configure range partitioning in SurrealDB for the orders table based on order_date.
1. Setting Up Dependencies
Ensure that you have the necessary dependencies in your Cargo.toml file:
[dependencies]
surrealdb = "1.0" # Replace with the latest version
tokio = { version = "1", features = ["full"] }
serde = { version = "1.0", features = ["derive"] }
serde_json = "1.0"
2. Defining Data Models
Define the data structures corresponding to the entities in the ERD using Rust structs with Serde for serialization.
use serde::{Deserialize, Serialize};
use surrealdb::Surreal;
#[derive(Serialize, Deserialize, Debug)]
struct Order {
id: String,
order_date: String, // Using String for simplicity; consider using chrono::DateTime
user: String, // Reference to User ID
total_amount: f64,
}
3. Connecting to SurrealDB and Applying Partitioning
Establish a connection to SurrealDB and apply range partitioning based on order_date.
#[tokio::main]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
// Connect to the database
let db = Surreal::new("http://localhost:8000").await?;
// Sign in as a namespace and database
db.signin(surrealdb::opt::auth::Basic {
username: "root",
password: "root",
}).await?;
// Select the namespace and database
db.use_ns("ecommerce").use_db("shop").await?;
// Define range partitioning on order_date for the orders table
let partitioning_query = r#"
DEFINE PARTITION orders_partition
PARTITION BY RANGE(order_date)
START '2024-01-01'
END '2025-01-01'
EVERY '1 MONTH';
"#;
db.query(partitioning_query).await?;
// Creating a new order
let new_order = Order {
id: "order_1".to_string(),
order_date: "2024-09-01T10:00:00Z".to_string(),
user: "user_1".to_string(),
total_amount: 699.99,
};
db.create("orders", &new_order).await?;
Ok(())
}
4. Verifying Partitioning
After implementing partitioning, verify that data is correctly distributed across partitions by querying specific partitions.
#[tokio::main]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
// Connect to the database
let db = Surreal::new("http://localhost:8000").await?;
// Sign in as a namespace and database
db.signin(surrealdb::opt::auth::Basic {
username: "root",
password: "root",
})
.await?;
// Select the namespace and database
db.use_ns("ecommerce").use_db("shop").await?;
// Query orders from September 2024
let query = r#"
SELECT * FROM orders_partition WHERE order_date BETWEEN '2024-09-01' AND '2024-09-30';
"#;
let result: serde_json::Value = db.query(query).await?;
println!("September Orders: {:?}", result);
Ok(())
}
Explanation of the Rust Code
Dependencies: The
surrealdbcrate is used to interact with SurrealDB, whiletokioprovides asynchronous runtime support.serdeandserde_jsonfacilitate serialization and deserialization of data structures.Data Models: The
Orderstruct represents an entity in the e-commerce platform, with fields corresponding to attributes defined in the ERD.Database Connection and Partitioning: The
Surreal::newfunction establishes a connection to SurrealDB. After authentication, the partitioning scheme is defined using a SurrealQL query that sets up range partitioning based onorder_date, dividing data into monthly partitions.CRUD Operations: The example demonstrates creating a new order and querying orders within a specific date range, showcasing how data is efficiently accessed within the defined partitions.
Verification: By querying a specific partition, the example verifies that data is correctly distributed, ensuring that the partitioning strategy is effectively implemented.
Benefits of Implementing Data Partitioning with Rust and SurrealDB
Integrating Rust with SurrealDB for data partitioning offers several advantages:
Performance: Efficient data partitioning reduces query latency by limiting the search scope to specific partitions, enhancing overall system performance.
Scalability: Partitioning allows the database to handle large datasets by distributing data across multiple nodes, facilitating horizontal scaling without performance degradation.
Manageability: Smaller, manageable partitions simplify data maintenance tasks such as backups, migrations, and archiving, making it easier to manage large-scale data environments.
Flexibility: SurrealDB’s support for various partitioning schemes, combined with Rust’s expressive type system, allows for the implementation of tailored partitioning strategies that align with specific application requirements.
By leveraging Rust’s performance and safety features alongside SurrealDB’s robust partitioning capabilities, developers can build scalable, high-performance applications capable of managing large-scale data efficiently.
Practical Example: Scaling an E-commerce Database with SurrealDB
To illustrate the principles discussed, let's consider a real-world case study of scaling an e-commerce database using SurrealDB. This example will encompass an Entity-Relationship Diagram (ERD) created with Mermaid and provide comprehensive Rust code to interact with the database, demonstrating the implementation of data partitioning, sharding, and scalability strategies.
Rust Code Example: Scaling with Partitioning and Sharding in SurrealDB
Below is a comprehensive Rust example demonstrating how to set up SurrealDB, define the data models, implement partitioning and sharding strategies, and perform CRUD operations for the e-commerce platform.
1. Setting Up Dependencies
Ensure that you have the necessary dependencies in your Cargo.toml file:
[dependencies]
surrealdb = "1.0" # Replace with the latest version
tokio = { version = "1", features = ["full"] }
serde = { version = "1.0", features = ["derive"] }
serde_json = "1.0"
chrono = { version = "0.4", features = ["serde"] }
2. Defining Data Models
Define the data structures corresponding to the entities in the ERD using Rust structs with Serde for serialization.
use serde::{Deserialize, Serialize};
use surrealdb::Surreal;
use chrono::{DateTime, Utc};
#[derive(Serialize, Deserialize, Debug)]
struct User {
id: String,
name: String,
email: String,
joined_at: DateTime<Utc>,
}
#[derive(Serialize, Deserialize, Debug)]
struct Product {
id: String,
name: String,
description: String,
price: f64,
category: String,
}
#[derive(Serialize, Deserialize, Debug)]
struct Category {
id: String,
name: String,
}
#[derive(Serialize, Deserialize, Debug)]
struct Order {
id: String,
order_date: DateTime<Utc>,
user: String,
total_amount: f64,
}
#[derive(Serialize, Deserialize, Debug)]
struct OrderItem {
id: String,
order: String,
product: String,
quantity: i32,
price: f64,
}
#[derive(Serialize, Deserialize, Debug)]
struct Review {
id: String,
user: String,
product: String,
content: String,
rating: i32,
created_at: DateTime<Utc>,
}
3. Connecting to SurrealDB and Implementing Partitioning
Establish a connection to SurrealDB and implement data partitioning based on order_date using range partitioning.
#[tokio::main]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
let db = Surreal::new("http://localhost:8000").await?;
db.signin(surrealdb::opt::auth::Basic {
username: "root",
password: "root",
}).await?;
db.use_ns("ecommerce").use_db("shop").await?;
// Define range partitioning on order_date for the orders table
let partitioning_query = r#"
DEFINE PARTITION orders_partition
PARTITION BY RANGE(order_date)
START '2024-01-01'
END '2025-01-01'
EVERY '1 MONTH';
"#;
db.query(partitioning_query).await?;
// Define sharding for the products table using hash partitioning on category
let sharding_query = r#"
DEFINE SHARD products_shard
SHARD BY HASH(category)
SHARD COUNT 4;
"#;
db.query(sharding_query).await?;
let new_user = User {
id: "user_1".to_string(),
name: "Alice Smith".to_string(),
email: "[email protected]".to_string(),
joined_at: Utc::now(),
};
db.create("users", &new_user).await?;
Ok(())
}
4. Scaling the Database with Sharding
Implement sharding for the products table to distribute data across multiple shards based on the category attribute.
#[tokio::main]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
let db = Surreal::new("http://localhost:8000").await?;
db.signin(surrealdb::opt::auth::Basic {
username: "root",
password: "root",
}).await?;
db.use_ns("ecommerce").use_db("shop").await?;
let sharding_query = r#"
DEFINE SHARD products_shard
SHARD BY HASH(category)
SHARD COUNT 4;
"#;
db.query(sharding_query).await?;
let new_product = Product {
id: "prod_2".to_string(),
name: "Laptop".to_string(),
description: "A powerful laptop suitable for all your computing needs.".to_string(),
price: 1299.99,
category: "cat_1".to_string(),
};
db.create("products", &new_product).await?;
Ok(())
}
5. Monitoring and Adjusting Partitioning and Sharding
Continuously monitor data distribution and query performance to ensure that partitioning and sharding strategies remain effective as data grows and access patterns evolve.
#[tokio::main]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
// Connect to the database
let db = Surreal::new("http://localhost:8000").await?;
// Sign in as a namespace and database
db.signin(surrealdb::opt::auth::Basic {
username: "root",
password: "root",
})
.await?;
// Select the namespace and database
db.use_ns("ecommerce").use_db("shop").await?;
// Query to check data distribution across shards
let shard_query = r#"
SELECT COUNT(*) FROM products GROUP BY category;
"#;
let shard_distribution: serde_json::Value = db.query(shard_query).await?;
println!("Shard Distribution: {:?}", shard_distribution);
// Analyze query performance metrics (pseudo-code)
// let performance_metrics = db.get_performance_metrics().await?;
// println!("Performance Metrics: {:?}", performance_metrics);
// Based on metrics, decide if re-partitioning or re-sharding is needed
Ok(())
}
Explanation of the Rust Code
Dependencies: The
surrealdbcrate is used to interact with SurrealDB,tokioprovides asynchronous runtime support,serdeandserde_jsonfacilitate serialization and deserialization of data structures, andchronohandles date and time.Data Models: Each struct represents an entity in the e-commerce platform. Fields correspond to attributes defined in the ERD, with appropriate data types. Relationships are represented using string references to related entity IDs.
Database Connection and Partitioning: The
Surreal::newfunction establishes a connection to SurrealDB. After authentication, range partitioning is defined on theorder_dateattribute for theorderstable, dividing data into monthly partitions.Sharding: Sharding is implemented for the
productstable using hash partitioning based on thecategoryattribute, distributing data across four shards to balance the load and enhance performance.CRUD Operations: The example demonstrates creating new records for users, categories, products, orders, order items, and reviews. Creating a new product in a specific shard showcases how sharding distributes data across different partitions.
Monitoring and Adjusting: The final code snippet illustrates how to query data distribution across shards and pseudo-code for analyzing performance metrics. This continuous monitoring allows for adjustments to partitioning and sharding strategies as data grows and access patterns change.
Benefits of Implementing Partitioning and Sharding with Rust and SurrealDB
Integrating Rust with SurrealDB for data partitioning and sharding offers several advantages:
Performance: Effective partitioning and sharding distribute the load, reducing query latency and preventing performance bottlenecks.
Scalability: These strategies enable horizontal scaling, allowing the database to handle increasing data volumes and higher concurrency levels without sacrificing performance.
Fault Tolerance: Sharding enhances fault tolerance by distributing data across multiple nodes, ensuring that the failure of one node does not compromise the entire database.
Manageability: Smaller, manageable partitions simplify data maintenance tasks such as backups, migrations, and data lifecycle management.
Flexibility: SurrealDB’s support for various partitioning and sharding schemes, combined with Rust’s powerful data manipulation capabilities, allows for the implementation of tailored strategies that align with specific application requirements.
By leveraging Rust’s performance and safety features alongside SurrealDB’s robust partitioning and sharding capabilities, developers can build scalable, high-performance applications capable of managing large-scale data efficiently.
Effective management of large-scale data in multi-model databases like SurrealDB is essential for ensuring performance, scalability, and reliability in modern applications. By understanding and addressing the challenges associated with storage efficiency, performance optimization, and scalability, developers can implement robust data management strategies that support the growing demands of their applications. Techniques such as data partitioning and sharding, coupled with thoughtful scalability strategies, enable databases to handle vast amounts of diverse data seamlessly. Additionally, meticulous data migration and transformation processes ensure that data remains consistent and optimized as systems evolve. Integrating these strategies with Rust’s powerful and safe programming capabilities further enhances the ability to build scalable, high-performance applications. Through careful design and strategic implementation, SurrealDB and Rust together provide a formidable combination for managing complex, large-scale data environments in modern software systems.
11.4 Performance Tuning and Monitoring
As databases grow in complexity and scale, maintaining optimal performance becomes a pivotal challenge for database administrators and developers alike. This is particularly true in the context of multi-model databases like SurrealDB, where diverse data structures coexist and interact. This section provides an in-depth exploration of performance tuning and monitoring within SurrealDB, covering a range of techniques from memory management to query and storage optimization. It also delves into the use of monitoring tools that enable real-time performance assessment, helping to identify and rectify bottlenecks before they impact the overall system performance.
Comprehensive Exploration of Performance Tuning and Monitoring
Performance tuning and monitoring are essential for ensuring that SurrealDB operates efficiently, especially as data volumes and query complexities increase. Effective performance management involves not only optimizing the database configuration and queries but also continuously monitoring system metrics to detect and address performance issues proactively. This section delves into the strategies and tools necessary for achieving and maintaining optimal database performance, emphasizing the importance of a holistic approach that encompasses memory management, query optimization, storage efficiency, and robust monitoring practices.
11.4.1 Introduction to Performance Tuning
Performance tuning in SurrealDB involves a meticulous approach to enhancing the database's efficiency and responsiveness. This process requires a deep understanding of the database's architecture, the nature of the workloads it handles, and the specific performance characteristics of the applications it supports. Key areas of focus include:
Memory Management
Optimizing how SurrealDB allocates and uses memory can significantly impact performance, particularly in handling large datasets and complex queries. Efficient memory management ensures that the database can process queries swiftly without being bogged down by excessive memory usage or memory leaks. Strategies for effective memory management include:
Configuring Memory Allocation: Adjusting SurrealDB’s memory settings to allocate sufficient resources for caching frequently accessed data, thereby reducing the need for disk I/O operations.
Monitoring Memory Usage: Continuously tracking memory consumption to identify and address potential memory bottlenecks before they affect performance.
Optimizing Data Structures: Utilizing memory-efficient data structures and algorithms to minimize memory overhead and enhance processing speed.
Query Optimization
Refining queries to make full use of indexes and to minimize costly operations like full table scans is essential for maintaining fast response times. Query optimization involves:
Leveraging Indexes: Ensuring that queries are designed to take advantage of existing indexes, reducing the need for extensive data scanning.
Simplifying Complex Queries: Breaking down complex queries into simpler, more efficient sub-queries that can be executed more quickly.
Analyzing Query Plans: Examining how SurrealDB executes queries to identify inefficiencies and optimize query paths.
Storage Optimization
Efficient data storage not only saves space but also speeds up data retrieval, contributing to overall performance enhancements. Storage optimization involves:
Data Compression: Reducing the size of stored data to save space and improve I/O performance.
Efficient Encoding Schemes: Using encoding methods that minimize storage requirements without sacrificing data integrity.
Storage Tiering: Implementing tiered storage solutions where frequently accessed data is stored on high-performance media, while less critical data resides on slower, more cost-effective storage.
Each of these areas requires specific strategies and a deep understanding of both the underlying database architecture and the operational workload. By focusing on these key aspects, developers and administrators can significantly enhance the performance and reliability of SurrealDB.
11.4.2 Monitoring Tools
Effective monitoring is crucial for maintaining and tuning the performance of SurrealDB. Monitoring tools provide insights into the database’s operational metrics, helping administrators track everything from query execution times to resource utilization. Utilizing the right monitoring tools enables proactive performance management, ensuring that potential issues are identified and addressed before they impact the system.
Built-in Database Logs
SurrealDB’s own logging mechanisms can offer immediate insights into performance issues and system operations. These logs can provide detailed information about query execution times, error rates, and system resource usage. By analyzing these logs, administrators can:
Identify Slow Queries: Detect queries that are taking longer than expected to execute, allowing for targeted optimization.
Monitor System Health: Keep track of system metrics such as CPU usage, memory consumption, and disk I/O to ensure that the database is operating within optimal parameters.
Detect Anomalies: Spot unusual patterns or anomalies in database operations that may indicate underlying issues.
Performance Dashboards
Performance dashboards provide a real-time graphical view of database metrics, enabling quick identification of performance degradation and its sources. These dashboards typically display key performance indicators (KPIs) such as:
Query Performance: Visual representations of query execution times and throughput.
Resource Utilization: Charts showing CPU, memory, and disk usage over time.
Error Rates: Graphs illustrating the frequency and types of errors occurring within the database.
Third-party Monitoring Solutions
Integrations with popular monitoring frameworks can offer extended capabilities, including alerts, detailed reports, and historical data analysis. Some widely used third-party monitoring solutions compatible with SurrealDB include:
Prometheus: An open-source monitoring system that collects and stores metrics as time-series data, providing powerful querying and alerting capabilities.
Grafana: A visualization tool that can create dynamic dashboards by pulling data from various sources, including Prometheus, to display real-time and historical performance metrics.
Datadog: A cloud-based monitoring and analytics platform that offers comprehensive observability across applications, infrastructure, and logs.
By leveraging these tools, administrators can gain a holistic view of SurrealDB’s performance, enabling informed decision-making and timely interventions to maintain optimal system performance.
11.4.3 Identifying Bottlenecks
Identifying and diagnosing performance bottlenecks is a critical skill in database management. In SurrealDB, bottlenecks can arise from a variety of sources, each requiring specific strategies to diagnose and resolve. Understanding how to pinpoint these issues is the first step in resolving them and can drastically improve the performance of the database.
Complex Queries
Poorly designed queries can consume disproportionate resources, especially if they involve multiple data models or lack proper indexing. Complex queries may involve:
Multiple Joins: Queries that join several tables or data models can lead to significant resource consumption and slower execution times.
Full Table Scans: Queries that require scanning entire tables due to missing or inefficient indexes can dramatically slow down performance.
Suboptimal Query Structures: Inefficient use of query constructs or unnecessary complexity can lead to longer execution times and higher resource usage.
Diagnostic Strategies:
Query Profiling: Use SurrealDB’s query profiling tools to analyze how queries are executed and identify inefficiencies.
Explain Plans: Generate and review explain plans to understand the execution path of queries and pinpoint areas for optimization.
Resource Contention
As the number of concurrent users or applications accessing the database increases, contention for CPU, memory, and I/O resources can lead to bottlenecks. Resource contention issues may manifest as:
High CPU Utilization: Excessive CPU usage can slow down query processing and overall system responsiveness.
Memory Exhaustion: Insufficient memory can lead to increased disk I/O and slower query performance.
I/O Bottlenecks: High disk I/O can delay data retrieval and affect the performance of read-heavy operations.
Diagnostic Strategies:
Resource Monitoring: Continuously monitor CPU, memory, and disk I/O metrics to identify patterns of resource contention.
Load Testing: Conduct load testing to simulate high-concurrency scenarios and observe how SurrealDB handles increased demand.
Configuration Settings
Suboptimal configuration settings for SurrealDB can also impede performance, especially if they fail to match the deployment environment's characteristics. Configuration issues may include:
Inadequate Memory Allocation: Insufficient memory allocated to SurrealDB can limit its ability to cache data effectively.
Improper Index Configuration: Incorrect or inefficient index settings can lead to slower query performance and increased maintenance overhead.
Network Configuration: Poor network settings can introduce latency and affect data transmission speeds between SurrealDB nodes and clients.
Diagnostic Strategies:
Configuration Audits: Regularly review and audit SurrealDB’s configuration settings to ensure they align with best practices and the specific needs of the deployment environment.
Performance Testing: Test different configuration settings to determine their impact on performance and identify the optimal configuration for your workload.
By systematically addressing these potential sources of bottlenecks, administrators can enhance the performance and reliability of SurrealDB, ensuring that it meets the demands of complex, large-scale applications.
11.4.4 Continuous Performance Improvement
Continuous performance monitoring and tuning should be an integral part of the database lifecycle management. This ongoing process involves:
Regularly Reviewing and Updating Configuration Settings
As workloads and data access patterns evolve, the database’s configuration settings may need to be adjusted to maintain optimal performance. Regular reviews ensure that settings such as memory allocation, cache sizes, and indexing strategies remain aligned with current operational demands. This proactive approach helps prevent performance degradation and ensures that SurrealDB continues to operate efficiently under changing conditions.
Continuously Refining Queries and Indexing Strategies
As new access patterns emerge and data grows, queries and indexing strategies must be refined to accommodate these changes. This involves:
Optimizing Existing Queries: Regularly analyze and optimize existing queries to ensure they remain efficient as data volumes increase.
Adding or Removing Indexes: Adjust indexing strategies based on evolving query patterns, adding indexes for frequently accessed fields and removing those that are no longer needed to reduce maintenance overhead.
Implementing Advanced Indexing Techniques: Explore advanced indexing options such as composite indexes or partial indexes to further enhance query performance.
Staying Updated with SurrealDB Releases and Features
SurrealDB continuously evolves, introducing new features and performance improvements in each release. Staying updated with these changes allows administrators to leverage the latest enhancements and tools for better performance management. This includes:
Adopting New Performance Features: Utilize newly introduced performance optimization features to further enhance database efficiency.
Applying Security and Stability Patches: Ensure that the database remains secure and stable by applying the latest patches and updates.
Participating in the Community: Engage with the SurrealDB community to stay informed about best practices, emerging trends, and innovative solutions for performance tuning.
By embracing a culture of continuous improvement, database administrators can ensure that SurrealDB remains performant, scalable, and resilient, supporting the evolving needs of their applications and organizations.
11.4.5 Tuning for Optimal Performance
To tune SurrealDB for optimal performance, consider the following practical steps. Each of these steps focuses on specific aspects of the database that can be fine-tuned to enhance efficiency and responsiveness.
Regular Index Review and Optimization
Periodically reviewing existing indexes and their impact on query performance is essential. This process involves:
Assessing Index Usage: Determine which indexes are frequently used by queries and which ones are seldom accessed.
Adding Necessary Indexes: Introduce new indexes for fields that are frequently queried but currently unindexed.
Removing Redundant Indexes: Eliminate indexes that are no longer necessary to reduce storage overhead and maintenance costs.
Optimizing Index Types: Evaluate the types of indexes in use (e.g., B-tree, hash) and ensure they are the most appropriate for the queries they support.
Example: If a new feature introduces queries that frequently filter orders by shipping_address, creating an index on the shipping_address field can significantly improve query performance.
Query Refactoring
Analyzing slow-performing queries using SurrealDB's query plan explanations helps identify inefficiencies. Refactoring these queries involves:
Simplifying Query Structures: Break down complex queries into simpler components to enhance readability and execution speed.
Minimizing Data Retrieval: Fetch only the necessary fields required for the application, avoiding the retrieval of unnecessary data.
Utilizing Efficient Join Operations: Optimize how joins are performed, ensuring they leverage existing indexes and reduce resource consumption.
Example: Instead of performing multiple nested queries to retrieve related data, restructure the query to use more efficient join operations that minimize the number of database hits.
Memory and Resource Allocation
Adjusting memory allocation and other resource settings in SurrealDB can better align with the operational demands of the applications it supports. This involves:
Allocating Sufficient Memory for Caching: Ensure that enough memory is allocated to cache frequently accessed data, reducing the need for repeated disk I/O operations.
Balancing CPU and I/O Resources: Distribute resources effectively to prevent any single component from becoming a bottleneck.
Configuring Connection Pools: Optimize connection pool settings to handle the expected number of concurrent connections without overloading the database.
Example: Increasing the cache size for frequently accessed tables can reduce query latency by allowing more data to be served from memory rather than disk.
11.4.6 Implementing Monitoring Solutions
Setting up effective monitoring for SurrealDB involves a combination of configuring SurrealDB to output detailed performance logs, integrating with monitoring systems, and establishing alert mechanisms. These steps ensure that administrators have comprehensive visibility into the database’s performance and can respond promptly to any issues.
Configuring SurrealDB to Output Detailed Performance Logs
SurrealDB’s logging capabilities can be fine-tuned to capture detailed information about database operations. This involves:
Enabling Verbose Logging: Configure SurrealDB to log detailed information about query executions, resource usage, and system events.
Setting Log Levels: Adjust log levels (e.g., DEBUG, INFO, WARN, ERROR) to capture the appropriate amount of detail without overwhelming the logging system.
Redirecting Logs: Ensure that logs are directed to appropriate storage locations for easy access and analysis.
Example: Configure SurrealDB to log query execution times and resource utilization metrics at the INFO level, enabling administrators to track performance trends over time.
Integrating SurrealDB with a Monitoring System
Integrating SurrealDB with a monitoring system that can track and visualize key performance metrics is crucial for real-time performance assessment. This integration typically involves:
Connecting to Monitoring Tools: Use APIs or plugins to connect SurrealDB with monitoring platforms like Prometheus, Grafana, or Datadog.
Defining Metrics to Monitor: Identify and configure the key metrics that need to be tracked, such as query latency, CPU usage, memory consumption, and disk I/O.
Creating Dashboards: Develop dashboards that provide a visual representation of the monitored metrics, allowing for quick identification of performance issues.
Example: Set up a Grafana dashboard that visualizes SurrealDB’s query execution times, memory usage, and CPU utilization, providing a real-time overview of database performance.
Establishing Alerts for Critical Thresholds
Setting up alerts ensures that any potential performance issues are addressed proactively. This involves:
Defining Alert Conditions: Specify the conditions under which alerts should be triggered, such as exceeding query latency thresholds or high CPU usage.
Configuring Alert Channels: Determine how alerts will be delivered, whether through email, SMS, Slack, or other communication channels.
Automating Alert Responses: Implement automated responses for certain alerts, such as scaling up resources or restarting services, to mitigate issues quickly.
Example: Configure an alert in Prometheus to notify administrators via Slack if query latency exceeds 500 milliseconds, enabling prompt investigation and resolution.
Section 1: Designing Complex Data Models
Key Fundamental Ideas:
Understanding Data Modeling: Explore the principles of data modeling, focusing on the challenges and strategies for modeling complex data in multi-model databases like SurrealDB.
Schema Design: Discuss the trade-offs between schema-less and schema-based approaches in SurrealDB.
Key Conceptual Ideas:
Balancing Normalization and Denormalization: Analyze when to normalize or denormalize data to optimize performance and maintainability in a multi-model environment.
Data Integrity Across Models: Explore techniques to ensure data integrity when managing relationships between document, graph, and relational data models.
Key Practical Ideas:
Designing for Flexibility and Scalability: Practical examples of designing flexible and scalable data models that can adapt to evolving application requirements.
Section 2: Indexing and Query Optimization
Key Fundamental Ideas:
Introduction to Indexing: Understand the role of indexing in improving query performance, particularly in a multi-model database like SurrealDB.
Types of Indexes: Overview of different indexing techniques available in SurrealDB, such as B-tree, hash, and GIN indexes.
Key Conceptual Ideas:
Optimizing Query Performance: Discuss strategies for optimizing queries by leveraging appropriate indexes and query planning techniques.
Indexing Trade-offs: Analyze the trade-offs between query performance and data modification performance when using indexes.
Key Practical Ideas:
Implementing Effective Indexing: Practical examples of implementing and tuning indexes for various data models in SurrealDB to enhance query performance.
Section 3: Managing Large-Scale Data
Key Fundamental Ideas:
Challenges of Large-Scale Data: Explore the unique challenges posed by managing large datasets in multi-model databases, including storage, performance, and scalability issues.
Data Partitioning and Sharding: Introduction to techniques for partitioning and sharding data to manage large-scale data effectively.
Key Conceptual Ideas:
Scalability Strategies: Discuss strategies for scaling SurrealDB to handle large volumes of data, including horizontal and vertical scaling techniques.
Data Migration and Transformation: Explore the considerations and strategies for migrating and transforming data within SurrealDB.
Key Practical Ideas:
Implementing Data Partitioning: Practical steps for partitioning data across multiple nodes in SurrealDB, ensuring efficient data distribution and query performance.
Section 4: Performance Tuning and Monitoring
Key Fundamental Ideas:
Introduction to Performance Tuning: Overview of key performance tuning techniques specific to SurrealDB, including memory management, query optimization, and storage optimization.
Monitoring Tools: Introduction to tools and techniques for monitoring the performance of SurrealDB in real-time.
Key Conceptual Ideas:
Identifying Bottlenecks: Discuss how to identify and diagnose performance bottlenecks in SurrealDB, with a focus on complex data structures and queries.
Continuous Performance Improvement: Explore the importance of continuous performance monitoring and tuning as part of the database lifecycle.
Key Practical Ideas:
Tuning for Optimal Performance: Step-by-step examples of tuning SurrealDB configurations and queries to achieve optimal performance based on specific use cases.
Implementing Monitoring Solutions: Practical guide to setting up and using monitoring tools to track and analyze SurrealDB performance over time.
11.5 Conclusion
Chapter 11 has provided you with the tools and insights necessary to effectively manage and optimize complex data structures within SurrealDB, a powerful multi-model database. By exploring advanced data modeling techniques, indexing strategies, and performance tuning, you have gained a deeper understanding of how to ensure your databases remain scalable, efficient, and responsive even as they grow in complexity and size. This chapter emphasized the importance of balancing normalization with denormalization, strategically implementing indexes, and continuously monitoring and tuning your database for peak performance. As you move forward, these skills will be crucial in developing robust, high-performance applications that can handle diverse and intricate data scenarios.
11.5.1 Further Learning with GenAI
As you deepen your understanding of multi-model databases, consider exploring these prompts using Generative AI platforms to extend your knowledge and skills:
Investigate how machine learning algorithms can be integrated with SurrealDB to predict and optimize query performance in real-time, focusing on how these algorithms can adapt to changing data patterns and workloads.
Explore the impact of advanced indexing strategies on the performance of multi-model queries in SurrealDB, particularly in highly interconnected data structures such as graphs and documents, and discuss how these strategies can be tailored to specific application needs.
Analyze the trade-offs between vertical and horizontal scaling in SurrealDB, and how each approach affects performance, resource utilization, and the overall system architecture, particularly in the context of large-scale deployments.
Discuss the challenges and solutions for implementing efficient data sharding in SurrealDB, especially for graph and document models, and explore how sharding can be used to enhance query performance and data distribution in distributed environments.
Examine how SurrealDB can be optimized for real-time analytics in high-frequency trading applications, focusing on the specific requirements for low-latency data processing and the integration of real-time data feeds.
Explore the role of AI-driven query optimization in multi-model databases like SurrealDB, focusing on how AI can enhance query planning and execution by dynamically adjusting query strategies based on real-time data and system performance metrics.
Investigate strategies for automating data migration processes within SurrealDB, ensuring minimal downtime and data integrity, and explore how these strategies can be applied in scenarios involving large-scale data migrations across different database models.
Evaluate the use of SurrealDB in managing large-scale IoT data, focusing on the challenges of storage, indexing, and real-time query performance, and discuss how SurrealDB's multi-model capabilities can be leveraged to handle diverse IoT data types.
Analyze the effectiveness of different monitoring tools and techniques in maintaining optimal performance in SurrealDB environments, particularly in terms of detecting and addressing performance bottlenecks and ensuring system stability.
Explore the potential of using SurrealDB in conjunction with blockchain technology to manage and verify complex data relationships, focusing on how blockchain can be integrated with SurrealDB's multi-model architecture to enhance data security and integrity.
Discuss the implications of multi-tenancy in SurrealDB, particularly how to ensure data isolation and performance in shared environments, and explore strategies for managing multi-tenant workloads effectively without compromising security or performance.
Investigate the integration of SurrealDB with AI-powered predictive maintenance systems, focusing on data collection, storage, and analysis, and discuss how SurrealDB's capabilities can be used to enhance the accuracy and reliability of predictive maintenance models.
Explore the challenges of implementing GDPR-compliant data management practices in SurrealDB, particularly regarding data deletion and anonymization, and discuss how SurrealDB can be configured to meet stringent data protection requirements.
Evaluate the use of SurrealDB for managing data in real-time gaming environments, focusing on latency, scalability, and consistency, and discuss how SurrealDB's features can be optimized to support the dynamic and interactive nature of gaming applications.
Analyze how SurrealDB can be leveraged to optimize supply chain management systems, focusing on complex data interactions across multiple models, and explore how SurrealDB's multi-model architecture can improve the efficiency and visibility of supply chain operations.
"By engaging with these prompts, you can deepen your expertise in advanced data management, pushing the boundaries of what’s possible with multi-model databases like SurrealDB. Let these explorations guide you toward mastering the intricacies of complex data environments, ensuring your applications are not only efficient but also future-proofed for the demands of tomorrow."
11.5.2 Hands On Practices
Practice 1: Designing and Implementing Complex Data Models
Task: Design and implement a multi-model data structure in SurrealDB that includes document, graph, and relational elements. For example, create a system that models a social network with user profiles (document model), relationships (graph model), and user activity logs (relational model).
Objective: Gain hands-on experience in designing complex data models that leverage SurrealDB’s multi-model capabilities, ensuring the models are both scalable and maintainable.
Advanced Challenge: Optimize your data model by balancing normalization and denormalization, considering the trade-offs in performance and data integrity. Test the model with sample data and adjust based on performance metrics.
Practice 2: Implementing and Optimizing Indexes
Task: Create and optimize indexes on your SurrealDB data models, focusing on improving the performance of complex queries across document, graph, and relational data.
Objective: Learn how to implement different types of indexes in SurrealDB and understand their impact on query performance.
Advanced Challenge: Experiment with various indexing strategies, such as compound indexes or partial indexes, and compare their performance impacts. Document the query performance before and after indexing, and analyze the trade-offs between query speed and data modification times.
Practice 3: Managing Large-Scale Data with Partitioning and Sharding
Task: Implement data partitioning and sharding strategies in SurrealDB to manage a large dataset. For instance, partition user data based on geographic location or time of activity, and shard the data across multiple nodes.
Objective: Develop skills in partitioning and sharding large datasets to improve scalability and performance in SurrealDB.
Advanced Challenge: Simulate a high-traffic environment by running concurrent queries and data modifications on your partitioned and sharded database. Analyze the performance and identify potential bottlenecks, then adjust your partitioning and sharding strategies to optimize performance further.
Practice 4: Performance Tuning and Continuous Monitoring
Task: Set up a performance monitoring system for SurrealDB using tools like Prometheus or Grafana. Identify and address performance bottlenecks by tuning configuration settings and optimizing query performance.
Objective: Learn how to continuously monitor and tune SurrealDB to maintain optimal performance, especially under varying loads.
Advanced Challenge: Create an automated alert system that notifies you of potential performance issues based on specific metrics (e.g., query latency, CPU usage). Implement automated scripts to apply performance tuning adjustments based on the alerts received.
Practice 5: Data Migration and Transformation
Task: Perform a data migration in SurrealDB, moving a large dataset from one schema to another while transforming the data structure to fit new application requirements. Ensure minimal downtime and data integrity during the migration.
Objective: Gain practical experience in planning and executing data migrations within SurrealDB, ensuring that the migration is efficient and that data remains consistent.
Advanced Challenge: Implement a rollback plan that allows you to revert the migration if issues arise. Test this rollback plan under various scenarios to ensure it can be executed reliably in a production environment.
Comments