Chapter 1
Understanding Multi-Model Databases
"The art of progress is to preserve order amid change and to preserve change amid order." — Alfred North Whitehead
In the constantly shifting landscape of data management, the advent of multi-model databases marks a revolutionary shift, reflecting a profound response to the increasingly complex and voluminous data challenges of the digital age. These databases integrate the functionalities of various traditional and modern database models—such as relational, document, graph, and key-value—into a cohesive, versatile framework. This integration not only breaks down the longstanding silos between different data handling techniques but also significantly enhances the efficiency and flexibility of data management systems. This chapter delves deep into the origins and evolutionary path of multi-model databases from their conceptual beginnings to their rise as fundamental components in tackling diverse data integration issues. It explores how the limitations of single-model databases catalyzed the development of multi-model technologies, and discusses the theoretical and practical implications of this evolution. By providing a nuanced understanding of the structural, operational, and strategic benefits of multi-model databases, this introduction sets the stage for a comprehensive exploration of their role in modern enterprises, their architectural underpinnings, and the specific advantages they offer over their single-model counterparts in managing the complexity and scale of contemporary data landscapes.
1.1 The Evolution of Database Models
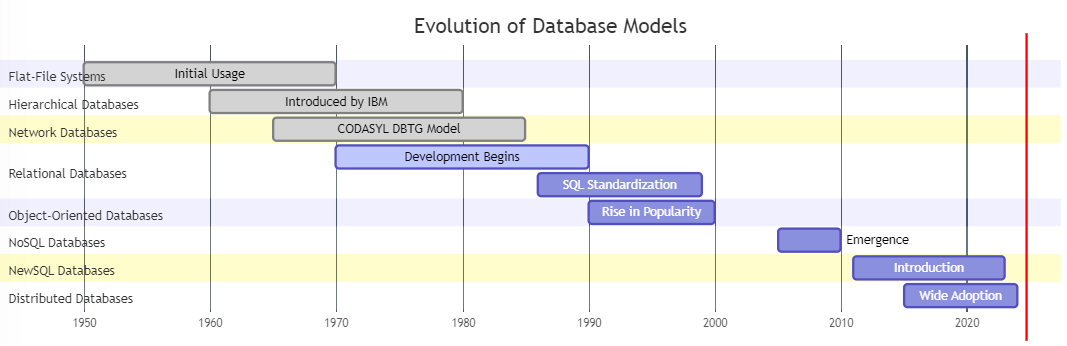
The landscape of database technology has undergone significant transformation since its inception, driven by the increasing complexity of data and the growing demands of modern applications. Early database systems were primarily designed to handle structured data, relying on hierarchical and network models that organized data in tree-like or graph-like structures. These models were sufficient for simpler data storage needs, where relationships between data elements were relatively straightforward. However, as data became more complex and applications demanded greater flexibility, these early models began to show their limitations. The introduction of the relational database model in the 1970s was a game-changing moment in data management. It offered a more abstract and powerful way to store and manipulate data using tables, rows, and columns, revolutionizing how databases were designed and used.
As the internet expanded and the need for handling unstructured or semi-structured data grew, new challenges arose that relational databases struggled to address efficiently. This gave rise to NoSQL databases in the late 2000s, offering schema-less, flexible data models that could handle large-scale, distributed data more effectively. These new models, including document-based, key-value, column-family, and graph databases, provided much-needed solutions for use cases that demanded high scalability and performance, such as social media platforms, e-commerce sites, and real-time analytics. The evolution of database models from structured to multi-model approaches reflects the changing landscape of data management, where diverse data types and workloads now require equally diverse database solutions.
1.1.1 From Hierarchical to Relational: The Early Foundations
None
In the early days of computing, data organization was relatively straightforward, but constrained by the limitations of hardware and storage systems. The hierarchical database model, one of the earliest approaches, was introduced in the 1960s. This model arranged data in a tree-like structure, where records had a parent-child relationship. While effective for certain use cases, the hierarchical model lacked flexibility. Data retrieval in this model required knowing the exact path, which made complex queries and cross-referencing between records cumbersome.
As data complexity grew, the network model emerged as an improvement. Developed during the 1970s, it allowed more flexible relationships between data records, where each record could have multiple parent and child nodes. However, the complexity of navigating these structures increased, limiting the model's scalability and usability for real-time applications. Both the hierarchical and network models were effective for early transaction processing systems but struggled with the growing need for more dynamic, interconnected data environments.
The advent of the relational database model in the 1970s, introduced by Edgar F. Codd, marked a revolutionary shift. Relational databases, which store data in tables and enable complex queries using Structured Query Language (SQL), quickly became the gold standard for data management. This model allowed for greater flexibility, as it abstracted the underlying data structure and provided a more intuitive query language. Relationships between data could be expressed via foreign keys, enabling users to efficiently query across multiple tables. The relational model significantly improved data organization, consistency, and retrieval speed, laying the foundation for modern database management systems (DBMS) like Oracle, MySQL, and PostgreSQL.
1.1.2 Emergence of NoSQL: A Response to New Challenges
By the early 2000s, the rise of the internet and the advent of big data introduced new challenges for relational databases. The traditional relational model excelled at managing structured data, but struggled with the demands of real-time applications, unstructured data, and horizontal scaling. As companies began generating massive amounts of data in various forms—text, images, social media posts, logs—the rigid schema and vertical scaling limitations of relational databases became a bottleneck.
This paved the way for the development of NoSQL databases, which offered a schema-less, more flexible approach to data storage. NoSQL databases—such as MongoDB, Cassandra, and Redis—eschewed the table-based structure of relational databases in favor of formats like key-value pairs, document stores, column families, and graph structures. These databases were designed to handle large volumes of data, distributed across multiple servers, making them ideal for handling big data and real-time processing needs.
While NoSQL databases addressed specific limitations of relational databases, they also introduced new complexities, particularly around data consistency and query flexibility. However, their ability to scale horizontally and handle a variety of data types made them indispensable for applications in areas like social media, e-commerce, and real-time analytics. NoSQL databases were not intended to replace relational databases entirely but offered an alternative for specific use cases where flexibility, scalability, and speed were prioritized over strict transactional consistency.
1.1.3 The Necessity of Evolution: Adapting to Technological Advancements
The rapid pace of technological innovation, particularly in the areas of cloud computing, big data, and real-time analytics, necessitated a fundamental shift in how data was stored and retrieved. The limitations of earlier models, especially the rigidity of relational databases and the complexity of hierarchical and network systems, could not keep pace with the growing needs of businesses and developers.
One of the key drivers behind the evolution of database models was the sheer volume and variety of data generated by modern applications. Relational databases, though robust and reliable, were designed for structured data with a predefined schema. However, the explosion of semi-structured and unstructured data—such as logs, JSON documents, and multimedia files—highlighted the need for more flexible data storage solutions. The rise of NoSQL databases was not just a technological advancement; it was a necessary adaptation to handle the growing complexity of data ecosystems.
The shift from monolithic systems to microservices and distributed architectures also influenced the evolution of database models. Relational databases, often running on single nodes, struggled with horizontal scaling, while NoSQL databases excelled in distributed environments, enabling businesses to scale out efficiently and maintain performance across geographically dispersed data centers.
1.1.4 Impact on Data Management Practices
The evolution of database models has fundamentally transformed how data is managed in modern systems. As new models emerged, so too did changes in data management practices, forcing businesses to adapt to new tools, strategies, and architectures. The flexibility of NoSQL databases allowed for rapid prototyping and development, as developers no longer needed to define a rigid schema before storing data. This agility proved essential in environments with rapidly changing data requirements, such as startups or dynamic web applications.
However, the adoption of NoSQL databases also required businesses to rethink their approaches to data consistency and transactions. Whereas relational databases enforced strict ACID (Atomicity, Consistency, Isolation, Durability) properties, many NoSQL databases favored eventual consistency models, where data might be inconsistent for a brief period but would converge over time. This trade-off between consistency and availability became a central consideration in the design of distributed systems, giving rise to the CAP theorem—which posits that a distributed database can only guarantee two of the three properties: Consistency, Availability, or Partition Tolerance.
The hybrid approach, combining relational and NoSQL systems within a single architecture, also gained popularity as businesses sought to leverage the strengths of both models. Multi-model databases, which can support multiple data models (relational, document, graph, etc.) under a single system, represent the next logical step in this evolution, offering the best of both worlds: the structure and consistency of relational databases with the flexibility and scalability of NoSQL.
1.1.5 Case Studies: Real-World Impacts of Database Evolution
The evolution of database models has had a direct impact on business outcomes and technological innovation. For example, Amazon DynamoDB, a NoSQL database, was designed to handle the massive scaling requirements of Amazon’s e-commerce platform, where traditional relational databases could not keep up with the demand during peak shopping periods. DynamoDB’s flexible key-value store allowed Amazon to build a highly scalable, fault-tolerant database system capable of handling millions of requests per second, ensuring seamless customer experiences even during high traffic.
Similarly, Facebook’s adoption of MySQL alongside HBase, a NoSQL database, exemplifies the hybrid database approach. Facebook uses MySQL for its structured, transactional data but relies on HBase to store large volumes of semi-structured data, such as posts, comments, and images, distributed across multiple data centers. This hybrid approach ensures that Facebook can maintain performance and reliability at scale, combining the strengths of both relational and NoSQL models.
In conclusion, the evolution of database models reflects the ongoing need for databases to adapt to new technological challenges. From the early hierarchical and relational systems to the rise of NoSQL and multi-model databases, each development has provided a stepping stone toward more efficient, scalable, and flexible data management solutions. Understanding this evolution is crucial for anyone navigating the complex landscape of modern data systems.
1.2 Core Characteristics of Multi-Model Databases
As data requirements have evolved, so too have the systems designed to store and manage it. The emergence of multi-model databases represents a significant advancement in addressing the diverse needs of modern applications. Unlike traditional single-model systems that are limited to supporting only one type of data model—such as relational, document, or graph—a multi-model database is designed to accommodate multiple data models within a single, unified platform. This flexibility allows organizations to streamline their data infrastructure, reducing the need for separate systems to handle different types of data. Instead of relying on distinct databases for different tasks, a multi-model database offers a more efficient approach by centralizing various models under one system, making it easier to manage and query data.
The core characteristics of multi-model databases extend beyond just flexibility. These systems are inherently designed for scalability, allowing them to handle growing amounts of data and increasing workloads across different models. Moreover, they offer powerful querying capabilities that can traverse multiple data models in a single operation, providing more comprehensive insights and minimizing the need for complex data integration processes. Multi-model databases also enhance consistency by allowing organizations to maintain a single source of truth across all data types, ensuring that relational data, graph data, and document data remain synchronized and up-to-date. Real-world implementations, such as the use of multi-model databases in e-commerce platforms and social media applications, demonstrate how these systems can manage diverse data workloads effectively, providing both flexibility and performance in environments with complex data requirements.
1.2.1 Defining Multi-Model Databases
At its core, a multi-model database is a data management system that supports more than one type of data model, enabling users to store, retrieve, and manipulate data in various formats. Traditional databases often require developers to choose a specific model, such as relational (for structured, tabular data) or document-based (for semi-structured or unstructured data), leading to a fragmented infrastructure when different models are needed. In contrast, a multi-model database combines these approaches within a single system, allowing developers to work with relational, document, key-value, graph, or even columnar models without having to integrate multiple databases.
The defining feature of a multi-model database is its flexibility in supporting different data structures natively, eliminating the need to maintain multiple, specialized databases for different data models. This enables businesses to simplify their database infrastructure while still addressing diverse application needs, from transactional systems to big data analytics.
Multi-model databases also often provide unified query languages, which allow users to interact with different data models through a common interface. For example, databases like SurrealDB allow for querying relational, document, and graph data using a single query language, reducing the complexity of managing and interacting with various data models.
1.2.2 Data Model Integration and Unification
One of the most significant benefits of multi-model databases is their ability to integrate various data models within a single environment. In traditional systems, different models are often housed in separate databases, each requiring distinct tooling, APIs, and infrastructure management. This leads to polyglot persistence, where a variety of database technologies are used within the same application or organization to manage different types of data. While polyglot persistence offers flexibility, it introduces complexity in data management, integration, and governance.
Multi-model databases offer a unified approach, allowing multiple data models to coexist and interoperate seamlessly. For example, an application that tracks social media interactions might store structured user data in a relational table, user posts in a document format, and relationships between users in a graph. In a polyglot system, these data models would reside in separate databases (e.g., PostgreSQL for relational data, MongoDB for documents, and Neo4j for graph data). However, a multi-model database enables these diverse models to be stored and queried within the same system, dramatically reducing the overhead of managing and synchronizing data across different platforms.
This integration offers significant operational advantages. By housing multiple models in one database, multi-model systems simplify data storage and retrieval, reduce the complexity of application development, and streamline maintenance processes. Furthermore, they enable organizations to handle diverse workloads, from transactional processing to complex analytical queries, within a single system.
1.2.3 Unified vs. Polyglot Persistence: A Strategic Comparison
The debate between unified multi-model databases and polyglot persistence strategies centers on how best to manage the diverse data needs of modern applications. In a polyglot persistence architecture, different databases are selected based on their specialized strengths. For example, relational databases excel at enforcing schema integrity and supporting complex joins, while NoSQL databases like MongoDB are better suited for unstructured data and flexible schema design. In this approach, each database is optimized for a particular use case.
However, polyglot persistence comes with significant drawbacks. Managing multiple databases means that developers must maintain separate query languages, APIs, and synchronization mechanisms, increasing the overall complexity of the system. Furthermore, data governance, consistency, and security can become fragmented as each database may require its own policies and management systems. This fragmentation can introduce challenges, particularly when data needs to be aggregated or correlated across systems.
A unified multi-model database, by contrast, provides a consolidated solution that eliminates the need for multiple database systems. It allows developers to interact with different data models using a single query interface, significantly reducing the complexity of data management. Moreover, a unified system simplifies data governance, as policies regarding security, consistency, and availability can be applied uniformly across all data models.
The choice between polyglot persistence and a multi-model database depends largely on the use case. While polyglot persistence may offer specialized performance benefits in certain scenarios, the simplicity, reduced overhead, and ease of governance provided by multi-model databases often make them the more attractive option for organizations seeking to streamline their data management.
1.2.4 Advantages of Data Model Integration
The integration of multiple data models into a single database system offers several key advantages, particularly in terms of infrastructure simplification, performance optimization, and data governance. One of the most compelling benefits is the ability to handle diverse workloads within the same system. By supporting relational, document, graph, and other models simultaneously, multi-model databases enable applications to manage a wide variety of data types without the need for separate storage solutions.
From an infrastructure perspective, this consolidation reduces the need for multiple database instances, which can result in lower maintenance costs, reduced operational complexity, and more efficient resource allocation. Furthermore, multi-model databases can optimize query execution across different models, allowing for cross-model querying, which enhances performance for complex analytical tasks.
In addition to simplifying infrastructure, multi-model databases make it easier to ensure data consistency and integrity. In a polyglot system, maintaining consistency between different databases often requires complex synchronization mechanisms. With multi-model systems, consistency can be managed centrally, and transactions can span multiple data models, ensuring that data remains consistent even when working across diverse formats.
Moreover, by providing a unified platform for storing and managing data, multi-model databases can significantly simplify data governance. Security policies, access control, and compliance requirements can be enforced uniformly across all data models, reducing the risk of vulnerabilities introduced by fragmented systems. This uniformity is particularly important for organizations that operate in highly regulated industries, such as finance or healthcare, where maintaining strict control over data is essential.
1.2.5 Real-World Implementations of Multi-Model Databases
Several organizations have embraced multi-model databases to improve their data management capabilities and streamline their infrastructure. One notable example is ArangoDB, a widely used multi-model database that supports document, graph, and key-value data models. ArangoDB’s ability to handle diverse data types has made it a popular choice for companies needing to manage both transactional and analytical workloads within a single system.
Another example is Couchbase, which integrates document and key-value storage while also supporting SQL-like querying. Couchbase has been widely adopted in industries such as retail and finance, where the flexibility to store structured and unstructured data in a scalable manner is crucial. The ability to handle both types of data with high performance has allowed companies to reduce their operational overhead and simplify their application architectures.
A more cutting-edge example is SurrealDB, a relatively new multi-model database that integrates relational, document, and graph data. SurrealDB has gained attention for its ability to support complex relationships and transactions across different data models, making it well-suited for modern applications that require real-time analytics and complex data interactions. The flexibility of SurrealDB allows developers to build applications that can scale across different use cases without needing to adopt multiple database systems.
In each of these cases, the adoption of multi-model databases has allowed organizations to achieve greater flexibility, improved performance, and more efficient data management processes. By reducing the need for multiple, specialized databases, these systems have simplified the development and maintenance of applications, allowing businesses to focus on innovation rather than infrastructure.
In conclusion, the core characteristics of multi-model databases—flexibility, data model integration, and unified governance—represent a significant step forward in addressing the complexities of modern data environments. By consolidating different data models into a single system, multi-model databases offer the best of both worlds: the specialized capabilities of polyglot persistence with the simplicity and efficiency of a unified platform. Understanding these characteristics is key to appreciating the future direction of database technology.
1.3 Technical Foundations of Multi-Model Databases
The success of a multi-model database hinges on its ability to support diverse data types while maintaining high performance, scalability, and consistency. These databases are built on a robust technical foundation that allows them to handle different data models simultaneously, such as relational, document, graph, and key-value data. One of the key enablers is the storage engine, which must be versatile enough to efficiently store and retrieve different types of data. Multi-model databases often employ multiple storage engines or use hybrid approaches to ensure that each data model operates optimally within its storage context. For example, document data may benefit from a more schema-less storage approach, while relational data requires structured, table-based storage. The ability to switch between storage strategies is critical in enabling multi-model databases to function seamlessly.
Another crucial element is indexing, which plays a pivotal role in ensuring that queries across different data models are executed quickly and efficiently. Multi-model databases utilize advanced indexing strategies to manage diverse workloads, such as creating specific indexes for relational tables, document fields, or graph edges. Scalability is another vital component; multi-model databases are designed to handle increasing amounts of data while distributing workloads across multiple nodes or clusters. This ensures that performance remains stable, even as data volumes grow. Additionally, consistency models must be carefully considered, especially in distributed environments where data integrity across various models can be challenging. Multi-model databases often offer flexible consistency levels, such as strong or eventual consistency, allowing users to balance between performance and data reliability based on specific application needs. By understanding and leveraging these technical foundations, developers can optimize multi-model databases to meet the performance and scalability demands of modern data-driven applications.
1.3.1 Storage Engines in Multi-Model Databases
At the heart of any database system is the storage engine, which determines how data is stored, retrieved, and managed on disk or in memory. In a multi-model database, the choice of storage engine is especially important because it must handle different types of data—relational tables, document structures, graphs, and key-value pairs—without compromising performance.
Multi-model databases often leverage pluggable storage engines to accommodate these diverse data structures. For instance, a multi-model database might use a B-tree or LSM-tree engine for relational and key-value data, while employing specialized engines like ROCKSDB for document or graph data. These engines optimize storage and retrieval for specific data models, allowing multi-model databases to efficiently manage mixed workloads.
The ability to switch between or configure different storage engines also plays a crucial role in scalability. Systems like ArangoDB and Couchbase allow for fine-tuning of storage engines based on the expected workload. For example, LSM-tree engines excel at handling write-heavy workloads by batching writes, while B-tree engines provide fast random reads, making them ideal for transactional queries.
Storage engines in multi-model databases are designed to strike a balance between performance and flexibility. Each engine is optimized for different operations—such as indexing, compaction, and garbage collection—ensuring that the database can scale horizontally while maintaining data integrity and performance.
1.3.2 Indexing Strategies for Diverse Data Types
Efficient data retrieval is a cornerstone of any database, and indexing plays a critical role in optimizing query performance. In multi-model databases, indexing strategies must be flexible enough to support multiple data models—relational, document, and graph—while providing fast, consistent access to data.
Relational databases typically rely on B-tree indexes to optimize searches and joins across tables. However, document-based models, which deal with semi-structured data like JSON, often benefit from secondary indexes or full-text search indexes, allowing for more flexible querying across nested structures. For instance, in Couchbase, developers can create secondary indexes on specific fields within documents to speed up queries that might otherwise require scanning entire documents.
Graph models require specialized graph traversal indexes that optimize pathfinding operations, such as discovering the shortest route between two nodes. In multi-model databases like ArangoDB, a combination of traditional indexes (for document and relational data) and graph traversal indexes enables efficient cross-model querying. The ability to switch between relational joins, document filtering, and graph traversal within a single query is a key strength of multi-model databases.
The flexibility of indexing in multi-model databases also extends to their compound indexing capabilities. By creating indexes that span multiple fields and data models, developers can optimize complex queries that combine relational, document, and graph data. This capability allows multi-model databases to provide performant queries across diverse datasets without requiring separate systems for each data model.
1.3.3 Scalability and Performance Considerations
Managing multiple data models within a single database introduces significant scalability and performance challenges. Unlike traditional single-model systems, multi-model databases must balance the needs of different data structures, which often have conflicting performance requirements.
One key aspect of scalability in multi-model databases is horizontal scaling—the ability to distribute data and queries across multiple servers. NoSQL databases, like those supporting document and key-value models, were designed with horizontal scaling in mind. By distributing data across clusters, multi-model databases can handle larger datasets and more concurrent queries. Systems like Couchbase and SurrealDB leverage distributed architectures to provide seamless scaling for both reads and writes, allowing them to support real-time applications without sacrificing performance.
However, the challenge in multi-model databases lies in efficiently scaling mixed workloads. Relational data, for example, often benefits from vertical scaling—improving the performance of a single, powerful machine—while document and graph data require horizontal scaling to distribute data across many nodes. Multi-model databases address this by offering hybrid scaling options, where different models can be scaled according to their specific requirements.
Caching and partitioning also play vital roles in optimizing performance. Multi-model databases often include sophisticated caching mechanisms that store frequently accessed data in memory, reducing the need for disk I/O and speeding up query execution. Partitioning, on the other hand, ensures that data is distributed evenly across nodes, reducing the risk of bottlenecks.
In terms of performance, multi-model databases need to strike a balance between consistency and availability—often referred to as the CAP theorem. By offering configurable consistency levels, such as eventual consistency or strict transactional consistency, multi-model databases allow developers to choose the optimal balance for their specific use case.
1.3.4 Consistency Models in Multi-Model Systems
Maintaining data consistency across different models is a critical challenge in multi-model databases. Traditional relational databases ensure strict ACID (Atomicity, Consistency, Isolation, Durability) compliance, guaranteeing that transactions are processed reliably. However, when dealing with distributed systems or NoSQL databases, strict consistency can introduce latency and reduce availability, especially in real-time applications.
To address this, multi-model databases support various consistency models that offer different levels of trade-offs between consistency, availability, and partition tolerance. The most common models include:
Eventual Consistency: Common in NoSQL systems, this model allows temporary data inconsistencies with the guarantee that the data will eventually become consistent. Eventual consistency is ideal for highly distributed systems where availability is prioritized.
Strong Consistency: Ensures that all reads reflect the most recent write, typically used in transactional systems. Multi-model databases like OrientDB offer strong consistency for relational operations while providing eventual consistency for other models like document and graph data.
Causal Consistency: Ensures that related changes are applied in a specific order, even in distributed environments. This model is beneficial for systems that require some level of causal ordering but do not need the strictness of strong consistency.
By offering multiple consistency models, multi-model databases provide flexibility in managing data integrity. Developers can choose consistency levels based on the type of operation—strong consistency for transactional operations, eventual consistency for less critical reads, or causal consistency for related updates across different models.
1.3.5 Practical Optimization Techniques for Multi-Model Databases
Optimizing multi-model databases for performance and scalability requires a deep understanding of the underlying technologies and workload requirements. Here are some key techniques for configuring and tuning multi-model databases:
Query Optimization: Leverage the native query optimization features provided by multi-model databases. For instance, SurrealDB and ArangoDB offer query optimizers that analyze the query plan and suggest the best execution path, especially for cross-model queries. By ensuring that indexes are used effectively, developers can significantly improve query performance.
Schema Design: Even though multi-model databases allow for flexible schema design, optimizing schema for each data model is essential. For relational data, ensure that foreign keys and indexes are properly defined to avoid costly joins. For document and graph models, denormalize data where appropriate to reduce the need for frequent cross-model queries.
Partitioning and Sharding: Distribute data across nodes efficiently by leveraging partitioning and sharding strategies. For large datasets, ensure that partitions are balanced to avoid hotspots that could slow down query performance. Multi-model databases like Couchbase allow for automatic sharding, distributing data across clusters to maintain load balance.
Caching: Use in-memory caching layers to store frequently accessed data, especially for read-heavy applications. This reduces the need to repeatedly access disk-based storage, improving response times.
Monitoring and Tuning: Continuously monitor the performance of your multi-model database using built-in tools or third-party solutions. Look for slow queries, unbalanced partitions, or high-latency transactions, and adjust configurations accordingly. Performance tuning should be an ongoing process to adapt to changing workloads.
In conclusion, understanding the technical foundations of multi-model databases is critical to unlocking their full potential. From the choice of storage engines and indexing strategies to scalability considerations and consistency models, these databases offer powerful tools for managing diverse data models within a single system. By applying practical optimization techniques, developers can ensure that their multi-model databases perform at their best, providing both flexibility and efficiency for modern data-driven applications.
1.4 Implementing Multi-Model Databases
The implementation of a multi-model database requires a blend of technical expertise and strategic planning to address the complexities inherent in managing multiple data models within a unified system. Unlike traditional single-model databases, which are optimized for a specific type of data—whether relational, document, or graph—a multi-model database must seamlessly integrate various models such as relational, document-based, graph, and key-value data. This integration allows for greater flexibility in handling diverse data workloads, but it also introduces specific challenges. One of the primary hurdles is ensuring the smooth installation and configuration of the system, particularly when balancing different storage engines and indexing strategies that each model requires. Understanding the underlying architecture is key to implementing a multi-model database effectively, as developers must ensure that the system is optimized to handle different data models without compromising performance.
Additionally, configuring a multi-model database requires careful attention to data integration and query execution. With multiple models in play, data integration can become complex, especially when dealing with relationships between different types of data (e.g., linking relational tables with graph nodes or document collections). Ensuring that the database can execute queries that traverse these models efficiently is crucial to its success. Common configuration challenges include managing indexing for diverse data types, setting up scalable storage systems, and ensuring the database can handle high concurrency in multi-user environments. Developers must also consider how to maintain consistency across models and determine the right balance between strong and eventual consistency based on the application’s needs. By addressing these technical challenges head-on and following best practices, the implementation of a multi-model database can provide a powerful, flexible solution that meets the diverse data requirements of modern applications.
1.4.1 Installation and Setup
Installing and setting up a multi-model database is a crucial first step toward harnessing its capabilities. Many multi-model databases, such as ArangoDB and Couchbase, offer streamlined installation processes that make it easier for developers to get started quickly. However, the installation may vary based on whether the database will be deployed locally, in a cloud environment, or as part of a distributed architecture.
Step-by-Step Installation Process
For the purposes of this guide, let’s walk through the general steps for setting up ArangoDB, a popular open-source multi-model database:
- Download and Installation:
- Visit the official website to download the appropriate version of ArangoDB for your operating system (Linux, macOS, or Windows).
- On Linux, installation can be simplified using package managers like APT or YUM, while macOS users can use Homebrew.
- Run the installation script, which installs the database along with necessary dependencies.
- Initial Setup:
- After installation, start the database using the command:
sudo systemctl start arangodb3- ArangoDB provides a Web Interface (typically available at
http://localhost:8529), where you can configure the initial database, users, and permissions.
- User and Database Creation:
- In the web interface, you’ll be prompted to create a root user for database administration.
- After that, create a new database where you can begin implementing various data models—relational, document, and graph.
- Environment Configuration:
- Set up environment variables for database connections and paths, which are essential for integrating ArangoDB with applications. For instance, you can export connection parameters to ensure smooth communication between your application and the database:
export ARANGODB_HOST=localhost export ARANGODB_PORT=8529
With the installation complete, the next step is to tackle the challenges related to configuration.
1.4.2 Configuration Challenges
Configuring a multi-model database requires careful attention to the nuances of handling multiple data models within one system. Each data model—relational, document, graph—has distinct storage, querying, and performance requirements, and misconfigurations can lead to suboptimal performance or data inconsistencies.
One of the most common challenges is optimizing storage and indexing strategies for each data model. For example, relational data benefits from B-tree indexes, while graph queries may require specialized graph traversal indexes. Configuring a database to handle these distinct indexing requirements without creating unnecessary overhead is essential for maintaining performance across different types of queries.
Another key challenge is ensuring efficient resource allocation. Multi-model databases often allow configuration of how much CPU, memory, and disk space is allocated to each data model. For example, relational data may demand more memory to optimize query joins, while document data might require more disk space for storing larger, semi-structured files like JSON. Improper allocation can result in performance bottlenecks, particularly in environments where the workload varies between transactional and analytical operations.
Finally, managing consistency levels across different models is a critical consideration. While relational databases typically enforce strong consistency, document or graph models might favor eventual consistency for performance reasons. A well-configured multi-model database should allow developers to fine-tune consistency settings for each model based on application needs.
1.4.3 Data Integration Challenges
Integrating disparate data types—such as relational tables, documents, and graph nodes—into a cohesive system introduces several complexities. One of the primary challenges is designing a schema that accommodates different data models without creating redundant data or causing conflicts during cross-model queries.
For example, relational data is inherently structured, with predefined tables, rows, and columns. In contrast, document models, which store data as JSON or BSON, are schema-flexible, allowing new fields to be added dynamically. Meanwhile, graph models represent data as nodes and edges, which may not fit neatly into either a table or document structure. The challenge lies in defining how these models interact with each other, particularly when relationships span multiple data models.
Cross-model relationships need special attention. For instance, consider an application that uses a relational model for storing customer data and a document model for storing product reviews. In a multi-model database, establishing links between customer records (relational) and their reviews (documents) requires designing an interface that enables efficient querying across both models. Without careful schema design, cross-model joins or traversals can become computationally expensive, leading to performance degradation.
Moreover, data normalization and denormalization strategies differ between models. Relational models typically require normalization to avoid data duplication, while document models benefit from denormalization to speed up queries. Deciding where to apply these strategies requires a deep understanding of the underlying data relationships and query patterns.
1.4.4 Schema Design for Multi-Model Databases
When designing a schema for a multi-model database, developers must consider the requirements of each data model while balancing the need for cross-model interaction. A well-designed schema should support efficient querying, minimize redundancy, and facilitate seamless data integration across models.
Schema Flexibility: One of the advantages of multi-model databases is that they support schema-on-read for models like document stores, where the structure of the data can change over time. However, this flexibility can lead to schema drift if not managed properly. Developers need to define clear rules for how new fields are added to documents and how those fields interact with relational data.
Foreign Keys and References: In relational databases, foreign keys enforce relationships between tables. However, in a multi-model database, relationships might extend across different models. For example, a customer ID in a relational table may reference a document in a document store or a node in a graph. Defining these cross-model references is crucial for ensuring that queries return accurate, consistent results.
Performance Considerations: Schema design directly impacts query performance. For example, denormalizing data in a document model might improve query speed for specific reads, but it could also lead to increased storage costs and complexity in maintaining data consistency across models. Balancing these factors is key to designing an efficient schema for multi-model databases.
1.4.5 Hands-On Setup Tutorial: Configuring ArangoDB for Multi-Model Use
To provide a practical understanding, let’s walk through setting up ArangoDB for a multi-model environment.
- Initialize the Database:
- Start by creating a new database using the ArangoDB web interface or via command-line tools. Let’s call this database
MultiModelDB.
arangosh> db._createDatabase("MultiModelDB"); - Start by creating a new database using the ArangoDB web interface or via command-line tools. Let’s call this database
- Create Collections for Each Model:
- Set up collections for the different data models:
- A collection for relational data (e.g., a
Customerscollection):
arangosh> db._create("Customers");- A collection for document-based data (e.g., a
Reviewscollection):
arangosh> db._createDocumentCollection("Reviews");- A collection for graph data (e.g., nodes and edges representing customer relationships):
arangosh> db._createEdgeCollection("Relationships"); - Define Cross-Model Relationships:
- Use foreign keys or references to link relational data with document or graph data. For example, a
CustomerIDin theCustomerscollection can reference documents in theReviewscollection:
arangosh> db.Customers.insert({ "CustomerID": 1, "Name": "John Doe" }); arangosh> db.Reviews.insert({ "ReviewID": 101, "CustomerID": 1, "Review": "Great service!" }); - Use foreign keys or references to link relational data with document or graph data. For example, a
- Configure Indexes:
- To optimize query performance, create indexes tailored to each data model. For example, create a secondary index on
CustomerIDin theReviewscollection to speed up lookup queries:
arangosh> db.Reviews.ensureIndex({ type: "hash", fields: ["CustomerID"] }); - To optimize query performance, create indexes tailored to each data model. For example, create a secondary index on
- Query Across Models:
- Finally, test querying across different models. For instance, retrieve all reviews for a particular customer using the following query:
arangosh> db._query('FOR c IN Customers FILTER c.CustomerID == 1 FOR r IN Reviews FILTER r.CustomerID == c.CustomerID RETURN {customer: c.Name, review: r.Review}');
This hands-on approach demonstrates the practical aspects of setting up and configuring a multi-model database like ArangoDB. Through proper schema design, configuration, and cross-model querying, developers can leverage the full potential of multi-model databases.
In conclusion, implementing a multi-model database involves careful planning, configuration, and understanding of the unique challenges posed by integrating disparate data models. By following best practices and applying practical setup techniques, organizations can optimize their database infrastructure to handle complex, multi-faceted data environments efficiently.
1.5 Future Trends in Multi-Model Databases
The landscape of multi-model databases is rapidly evolving as advancements in technology, big data, and artificial intelligence (AI) drive new innovations and adoption trends. One of the most significant trends is the integration of AI-driven capabilities within multi-model databases. These databases are beginning to leverage machine learning algorithms to optimize query performance, predict data access patterns, and automate routine database management tasks. AI-powered query optimization, for example, can significantly reduce the time and complexity involved in handling cross-model queries, providing more efficient results for complex data relationships. As these systems become smarter, they will be able to anticipate user needs, making data retrieval faster and more accurate. Furthermore, multi-model databases are increasingly being adopted by industries that handle large volumes of diverse data, such as healthcare, finance, and e-commerce, where the ability to manage relational, document, and graph data within one system is essential.
In addition to AI integration, the future of multi-model databases will also be shaped by the growing demands of big data and regulatory compliance. As organizations continue to generate massive amounts of structured and unstructured data, multi-model databases will play a key role in providing scalable solutions for data storage, retrieval, and analysis. However, this growth comes with its own set of challenges. Regulatory frameworks, such as GDPR and data privacy laws, will require multi-model databases to implement more robust security features and ensure compliance across different data models. Another emerging trend is the increased focus on hybrid cloud architectures, where multi-model databases will need to support seamless data integration across on-premise and cloud environments. Organizations looking to integrate multi-model databases into their future data management infrastructure must consider these trends and adopt strategies that enable scalability, compliance, and efficient data handling in an ever-evolving technological landscape.
1.5.1 Innovative Developments in Multi-Model Databases
As data complexity grows, so too does the need for databases to intelligently manage and process diverse data types. One of the most exciting trends is the integration of AI-driven data management into multi-model databases. AI and machine learning algorithms are increasingly being applied to optimize data indexing, query execution, and even the automatic selection of data models. For instance, future multi-model databases may use AI to determine the optimal storage structure for a dataset, whether it's better suited to a relational, document, or graph model based on the nature of the queries being run.
Another innovation is the development of automatic model selection mechanisms. In traditional systems, developers must manually choose and configure data models for specific use cases, but upcoming multi-model databases are being designed to make these decisions autonomously. These databases will analyze the workload and data structure and dynamically adapt their underlying models for improved performance and scalability. Such advancements will significantly reduce the complexity of managing diverse data models and lower the barrier for businesses to adopt multi-model solutions.
1.5.2 Industry Adoption Trends and Growth Areas
Multi-model databases are rapidly gaining traction across industries as organizations seek to consolidate their data infrastructure. According to recent market studies, the global demand for multi-model databases is expected to grow exponentially over the next few years. Companies in sectors such as finance, healthcare, and e-commerce, where diverse datasets are common, are leading the charge in adopting multi-model solutions. The need to process and analyze structured, semi-structured, and unstructured data within the same system is driving this surge in adoption.
Moreover, as the line between transactional and analytical processing continues to blur, more industries are adopting hybrid transactional/analytical processing (HTAP) systems, which multi-model databases support natively. HTAP allows organizations to perform real-time analytics on transactional data without requiring separate analytical systems, making it a compelling use case for businesses that rely on up-to-the-minute insights, such as retail or logistics.
Projected growth areas include cloud-based multi-model databases, which offer scalability and ease of integration with modern applications. Cloud providers are increasingly integrating multi-model capabilities into their platforms, making it easier for businesses to adopt without needing extensive on-premises infrastructure. This trend is likely to accelerate as more organizations migrate their workloads to the cloud.
1.5.3 Impact on Big Data and AI
Multi-model databases are uniquely positioned to address the growing demands of big data analytics and artificial intelligence. With their ability to support multiple data models, these databases provide an ideal foundation for handling the diverse and complex data sets required by modern AI and machine learning algorithms. For example, a multi-model database can store structured training data in relational tables while managing unstructured data, such as images or logs, in document or graph formats. This flexibility allows AI systems to draw insights from a wider range of data sources without the need for extensive data transformation or migration between systems.
In the realm of big data, multi-model databases offer significant advantages by allowing real-time processing and querying across different data types. Traditional data lakes often struggle with performance and consistency issues when dealing with mixed data formats. Multi-model databases, however, are capable of integrating these disparate data types within a unified query framework, enabling faster and more accurate analysis of big data.
As AI continues to evolve, the seamless interaction between data models provided by multi-model databases will become increasingly critical. The ability to perform complex queries that span relational, document, and graph data will be essential for developing next-generation AI applications, including autonomous systems, real-time decision-making engines, and predictive analytics.
1.5.4 Regulatory and Security Implications
The widespread adoption of multi-model databases also brings regulatory and security challenges, particularly in industries that handle sensitive or regulated data. With the integration of multiple data models, ensuring data security across diverse structures becomes more complex. Each data model may have unique security requirements, and enforcing consistent security policies across them can be challenging.
Data privacy regulations such as the General Data Protection Regulation (GDPR) and California Consumer Privacy Act (CCPA) impose strict rules on how data must be stored, processed, and protected. Multi-model databases must support advanced encryption techniques, role-based access control, and auditing features to ensure compliance with these regulations. Additionally, the challenge of managing data sovereignty—ensuring that data remains within certain geographic boundaries—becomes more complicated in multi-model systems that store data across different models and locations.
On the security front, multi-model databases must incorporate robust authentication and authorization mechanisms that span all supported data models. Since different models often require different access controls (e.g., row-level security in relational data vs. node-level security in graph data), developers and administrators need tools to manage security comprehensively across models.
1.5.5 Strategic Planning for Future Adoption
For organizations looking to adopt multi-model databases as part of their future-proof data management strategy, several best practices should be considered:
Assess Current and Future Data Needs: Organizations should begin by analyzing their existing data landscape to determine how multi-model databases can streamline operations. This assessment should include an evaluation of the types of data being collected and processed (relational, document, graph, etc.) and the current pain points associated with managing those data models separately.
Plan for Scalability: One of the major advantages of multi-model databases is their ability to scale horizontally. Businesses should anticipate future data growth and ensure that the multi-model database they choose can scale to meet those needs, both in terms of data volume and query performance.
Ensure Regulatory Compliance: Before adopting a multi-model database, organizations must ensure that it supports the necessary security and compliance features for their industry. This may include encryption at rest and in transit, fine-grained access controls, and compliance certifications (e.g., SOC 2, HIPAA, GDPR).
Leverage Cloud-Based Solutions: For companies seeking to minimize infrastructure management, cloud-based multi-model databases provide an attractive option. These solutions offer automatic scaling, high availability, and integrated security features, allowing businesses to focus on data management without worrying about the underlying infrastructure.
Invest in Training and Skill Development: Adopting multi-model databases requires new skills and expertise, particularly for database administrators and developers. Organizations should invest in training their teams to understand how to work with multiple data models, configure complex systems, and optimize query performance across diverse datasets.
By strategically planning for the adoption of multi-model databases, businesses can not only solve current data challenges but also position themselves to take advantage of emerging trends in data management, AI, and big data.
In conclusion, the future of multi-model databases is bright, with ongoing innovations and growing industry adoption. As AI and big data continue to evolve, multi-model databases will play a crucial role in managing complex data ecosystems. Organizations that adopt these systems early will be well-positioned to navigate the challenges of modern data management and capitalize on new opportunities for innovation.
1.6 Conclusion
Chapter 1 has established a comprehensive foundation for understanding the significance and functionality of multi-model databases. Through the exploration of their evolution from traditional database systems to the integrated, versatile frameworks they are today, we've seen how these systems are uniquely poised to manage the diverse and complex data landscapes of modern enterprises. Multi-model databases not only enhance operational efficiency but also provide strategic flexibility, allowing organizations to leverage their data assets more effectively in a competitive environment. As the data management needs of organizations continue to evolve with technological advances, the role of multi-model databases is set to become even more pivotal, offering scalable solutions that can adapt to varying data types and complex application requirements.
1.6.1 Further Learning with GenAI
As you deepen your understanding of multi-model databases, consider exploring these prompts using Generative AI platforms to extend your knowledge and skills:
Analyze how integrating AI and machine learning in multi-model database management can automate data handling, enhance query performance, and proactively address system inefficiencies, particularly in large-scale environments.
Investigate the role of emerging technologies like blockchain and IoT in enhancing the security, transparency, and efficiency of multi-model databases within modern data ecosystems, focusing on real-world applications.
Evaluate the complexities of managing data governance in multi-model databases, especially in sectors with strict regulatory demands, by exploring how these databases maintain compliance, privacy, and security while adapting to changing legal landscapes.
Discuss potential future innovations in database technology that could augment or supplant current multi-model architectures, such as quantum computing or decentralized databases, and how these advancements might influence the IT landscape.
Examine the strategic implications of deploying multi-model databases within hybrid and multi-cloud environments, highlighting the challenges and strategies associated with ensuring data synchronization, consistency, and disaster recovery.
Consider the impact of real-time data processing capabilities in multi-model databases and how they transform industries requiring immediate data insights, such as finance, telecommunications, healthcare, and e-commerce.
Explore how multi-model databases can support large-scale machine learning and AI projects by providing diverse datasets that are easily accessible, queryable, and integrable, facilitating more complex and accurate models.
Analyze the trade-offs between using multi-model databases and specialized single-model databases in scenarios demanding ultra-high performance, specialized data processing, or strict compliance, considering both current and future industry trends.
Discuss how multi-model databases can be optimized for high-availability and disaster recovery environments to support mission-critical applications across diverse industries, with a focus on techniques such as data replication, clustering, and fault tolerance.
Investigate how principles of data lake architecture can be adapted within multi-model databases to enhance data flexibility, scalability, and the ability to handle unstructured, semi-structured, and structured data efficiently.
Evaluate the challenges and techniques involved in migrating legacy systems to multi-model databases, including strategies for minimizing downtime, ensuring data integrity, and achieving seamless transitions with minimal business disruption.
Examine how the growing trend towards data democratization is supported by multi-model databases, particularly their capacity to provide comprehensive, secure, and role-based access to diverse data sets for varied user groups within an organization.
Explore the potential for multi-model databases to enhance personalized customer experiences by leveraging integrated data models that provide deeper, more actionable insights into customer behaviors, preferences, and trends.
Assess the implications of multi-model databases for global data regulations, such as GDPR and CCPA, and how businesses can leverage these systems to enhance compliance through built-in privacy controls, data lineage tracking, and automated reporting.
Investigate the role of multi-model databases in predictive analytics, particularly their ability to ingest, integrate, and analyze diverse data sources in real-time to forecast trends, behaviors, and business outcomes.
Consider how the widespread adoption of multi-model databases affects the role, skills, and responsibilities of database administrators, data architects, and developers within organizations, focusing on the need for continuous learning and adaptation.
Discuss advancements in user interface and user experience design for multi-model database systems that accommodate diverse user interactions, including visualization tools, query builders, and intuitive management dashboards.
Analyze how version control, schema evolution, and data consistency are managed in multi-model databases, especially in agile development environments where continuous integration and continuous deployment (CI/CD) are critical.
Explore the impact of edge computing on multi-model databases, focusing on how data management at the edge can be optimized using these technologies to reduce latency, enhance real-time decision-making, and improve overall system efficiency.
Evaluate the role of multi-model databases in supporting IoT and AI at scale, particularly in processing, storing, and analyzing vast amounts of data generated by millions of devices and sensors, ensuring both efficiency and scalability.
These detailed and probing questions are designed to enhance your understanding of multi-model databases, pushing you to consider both theoretical aspects and practical implementations as you progress through the book and beyond.
1.6.2 Hands On Practices
Practice 1: Installing and Configuring Your First Multi-Model Database
Task: Install a popular multi-model database platform (e.g., ArangoDB, OrientDB) and configure it to support both document and graph data models.
Objective: Gain practical experience in setting up a multi-model database and understand the basic configuration necessary to support multiple data types.
Advanced Challenge: Implement security measures such as role-based access control and data encryption. Test the security setup by simulating common security threats and recording the system’s response.
Practice 2: Integrating Data Models
Task: Create a database schema that integrates document and relational models to manage customer and transaction data.
Objective: Learn how to design and implement a schema in a multi-model database that can handle complex data relationships efficiently.
Advanced Challenge: Develop a script that migrates existing data from a relational database into the new multi-model database without downtime or data loss.
Practice 3: Query Optimization in Multi-Model Databases
Task: Write and optimize queries that interact with both document and graph data models, focusing on complex queries that span both models.
Objective: Understand how to construct and optimize queries in a multi-model environment to improve performance and response times.
Advanced Challenge: Analyze query execution plans and tweak database settings to optimize query performance further. Document the changes in performance metrics after each optimization.
Practice 4: Data Migration Simulation
Task: Migrate sample data from a traditional SQL database to a multi-model database, ensuring that all relationships are preserved and optimized for the new environment.
Objective: Experience the practical challenges of data migration to a multi-model database and learn how to preserve data integrity and relationships during the migration.
Advanced Challenge: Automate the migration process using custom scripts and provide rollback capabilities to ensure data safety in case of migration failures.
Practice 5: Multi-Model Database Administration
Task: Use the administrative tools of your multi-model database to set up monitoring, manage backups, and configure scalability options.
Objective: Acquire hands-on experience in the daily administration tasks of a multi-model database, including performance monitoring and backup management.
Advanced Challenge: Set up a simulated high-availability cluster for your multi-model database and test failover scenarios to ensure that the database can handle node failures gracefully.
Comments